Back in 2018, during my master in Data Science, I started the emlearn project – implementing classic Machine Learning models designed to run on microcontrollers and embedded devices (aka “TinyML”).
Back then, the primary purpose was to learn the ins and outs of these algorithms, to make sure I really understood them well. Thinking about how the algorithms can be implemented efficiently in terms of RAM usage, storage space and CPU time is excellent for that purpose. But I always made sure to keep the code at production-quality, with a decent set of automated tests.
emlearn in use
Fast-forward 5 years, and emlearn has actually been used in a wide range of real-world projects, which is fantastic. Due to the open-source nature, everyone can just download it and use it for whatever they want – so there are probably many uses we will never hear about. And that is fine 🙂 But, there are some uses that I do know of. So here is a small selection of some of the projects using emlearn.
These projects highlight some of the typical characteristics for projects where emlearn is a good fit. Sensor data is analyzed on-device using a combination of Digital Signal Processing and Machine Learning. The extracted information is a low rate data-stream which can then be transmitted wirelessly. All of this can be done on low-cost hardware using general-purpose microcontrollers. Many tasks can also be done at low-power and run on battery.
Locating faults in the electrical power grid

Researchers from Sandia National Laboratories developed a system to identify the origin of faults in the power grid. When an abrupt fault occurs in a power transmission line, this causes a wave that propagates along the line. The wave is influenced by the electrical characteristics of the line as it travels along to other locations in the grid. The researchers used a combination of Digital Signal Progressing and Random Forest classifier to analyzes the signature of an incoming wave, and determines where the fault originated. They tested the system by injecting faults in a simulated model of a grid, and then ported the procedure to a DSP board from Texas Instruments.
Being able to automatically locate failures that occur in grid power lines is key to being able to dispatch maintenance crews to the right place, and could enable quicker recovery times after failures.
Breathing rate estimation in wearables

Researchers at Samsung used a combination of motion data from the accelerometer and sound data from the microphone on Samsung Galaxy earbuds to estimate breathing rate. First, breathing rate estimation is attempted using the accelerometer. If no estimation can be made, then the audio microphone data is used to estimate breathing rate. This multi-modal approach handles a wide range of cases, which they tested both in a laboratory and home setting. The battery consumption was low enough that the measurements could run continuously.
This kind of technology could be especially useful for people with respiratory diseases, who often need to check their breathing rate to manage and quantify their lung condition.
Activity monitoring for milk cows

Abhishek Damle, who was a master student at Virginia Tech in 2022, developed a battery-powered sensor that tracks cattle activity. The sensor is mounted on the cow’s halter, and uses a low-power accelerometer to sense motion. A decision tree is used to classify whether the cow is lying/walking/standing/grazing/ruminating. The detected activity is then transmitted LoRaWAN to a central location. They estimate that doing the machine learning on-sensor it consumes under 1 mW, which is 50 times less than if transmitting the raw data.
The activity data can be used to detect abnormal behavior in a cow, which can indicate health issues or other problems.
Recent developments
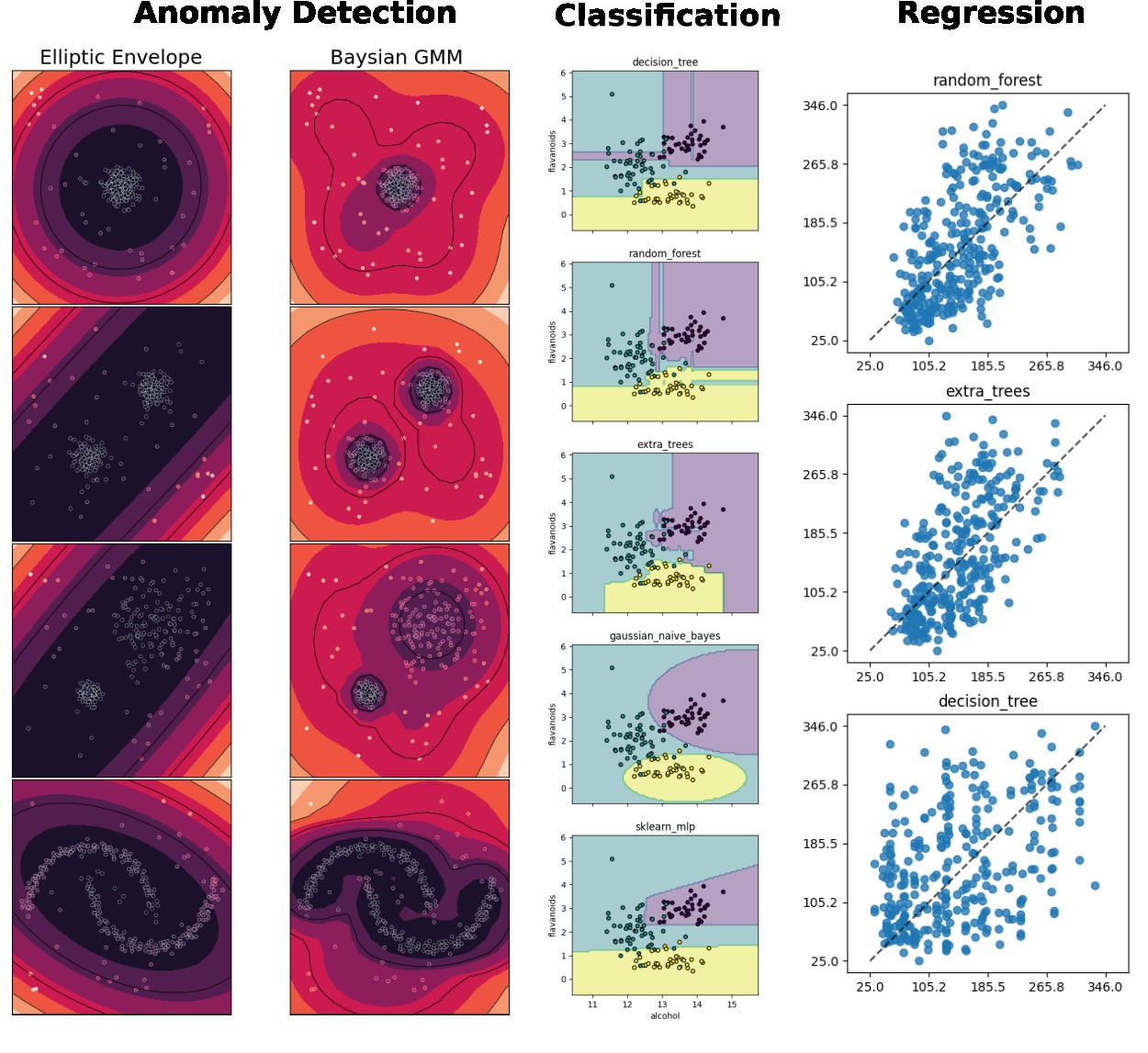
Classification, regression and anomaly detection
emlearn allows converting scikit-learn and Keras models trained in Python into efficient and portable C code. The first versions of only supported classification. Over the last years, we have also added support for regression and anomaly/outlier detection for a range of models.
Improved documentation
To facilitate further usage, I decided to do a pass to improve the documentation this summer.
Now there is more detailed documentation for Getting Started, that covers setting up and running the first model – be it on your PC, on Arduino, or running in a Web browser. There are also task-oriented pages in the user-guide – covering Classification, Regression, Anomaly Detection, Event Detection (for now).
MicroPython support
Whereas C is the lingua franca for embedded/firmware engineers, Python is the lingua franca for Data Scientists and Machine Learning Engineers.
emlearn itself is written in portable C99, and makes it easy to train in Python (on computer) and deploy to C (on device).
This is practical, but for some users and applications it could be even nicer to do also the device code in Python. This is now made easy with emlearn-micropython.
The MicroPython project is a Python (3.x) implementation designed for microcontrollers. It is around 10 years old by now, and has a good level of maturity. It is a very efficient and compact Python implementation, and runs on 32-bit devices with at least 256k of code space and 16k of RAM.
The emlearn-micropython are released as .mpy modules, which can be added to an existing board by copying it over USB/serial/WiFi. No rebuilding or flashing of the firmware needed! This uses the dynamic native modules feature in MicroPython. This is really quite magical, and lets us realize a workflow which has the convenience of Python, and the efficiency of C.
Example code for host
# Train a model using scikit-learn
estimator = RandomForestClassifier(n_estimators=3, max_depth=3, max_features=2, random_state=1)
estimator.fit(X, y)
# Convert model using emlearn
cmodel = emlearn.convert(estimator, method='inline')
# Save as loadable .csv file
cmodel.save(file='xor_model.csv', name='xor', format='csv')Example code for device
import emltrees
import array
model = emltrees.new(5, 30) # ensemble of up to 5 trees and 30 decision nodes
# Load a CSV file with the model
with open('xor_model.csv', 'r') as f:
emltrees.load_model(model, f)
# run inference with the model
examples = [
array.array('f', [0.0, 0.0]),
array.array('f', [1.0, 1.0]),
array.array('f', [0.0, 1.0]),
array.array('f', [1.0, 0.0]),
]
for ex in examples:
result = model.predict(ex)
print(ex, result)There are some existing projects that allow to generate (Micro)Python code for ML models, such as m2cgen and everywhereml. But while MicroPython is a pretty efficient Python, a C implementation should still be able to do better. To test this, I ran some quick benchmarks. These were performed on a RP2040, an affordable and popular ARM Cortex M0 chip.
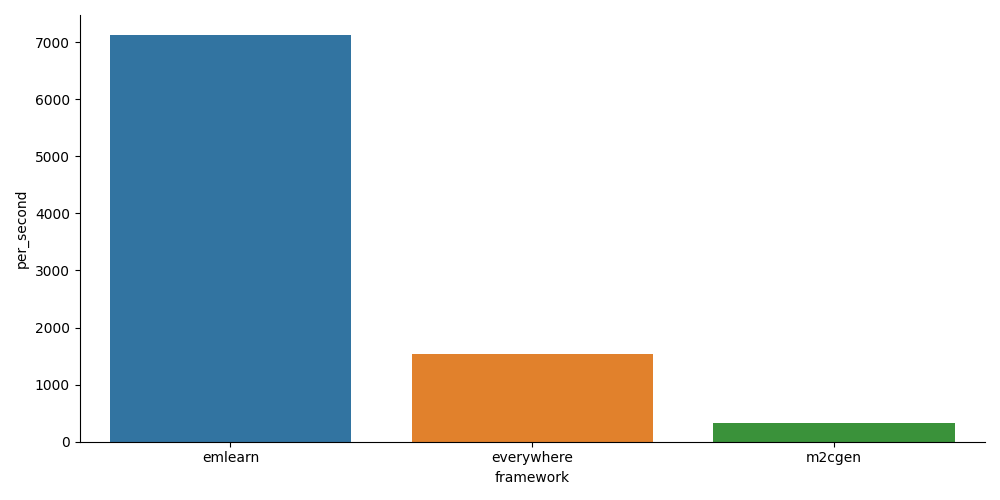
Y axis is the number of samples per second (higher is better).
As expected, the emlearn approach is many times faster than pure-Python based approaches. This could be further increased by enabling fixed-point/integer support in emlearn.
The TinyML wave has only just begun
emlearn is a library for Machine Learning on microcontrollers and embedded systems – often referred to as TinyML. There are over 20 billion microcontrollers shipped every year. From 2022 it is estimated that over 2 billion of these are TinyML devices, up from 15 million in 2019[1].
So it is still very early days for this field. And it will be very interesting to see where emlearn goes in the next 5 years.