At The Grid we do a lot of computationally heavy work server-side, in order to produce websites from user-provided content. This includes image analytics (for understanding the content), constraint solving (for page layout) and image processing (optimization and filtering to achieve a particular look). Currently we serve some thousand sites, with some hundred thousands sites expected by the time we’ve completed beta – so scalability is a core concern.
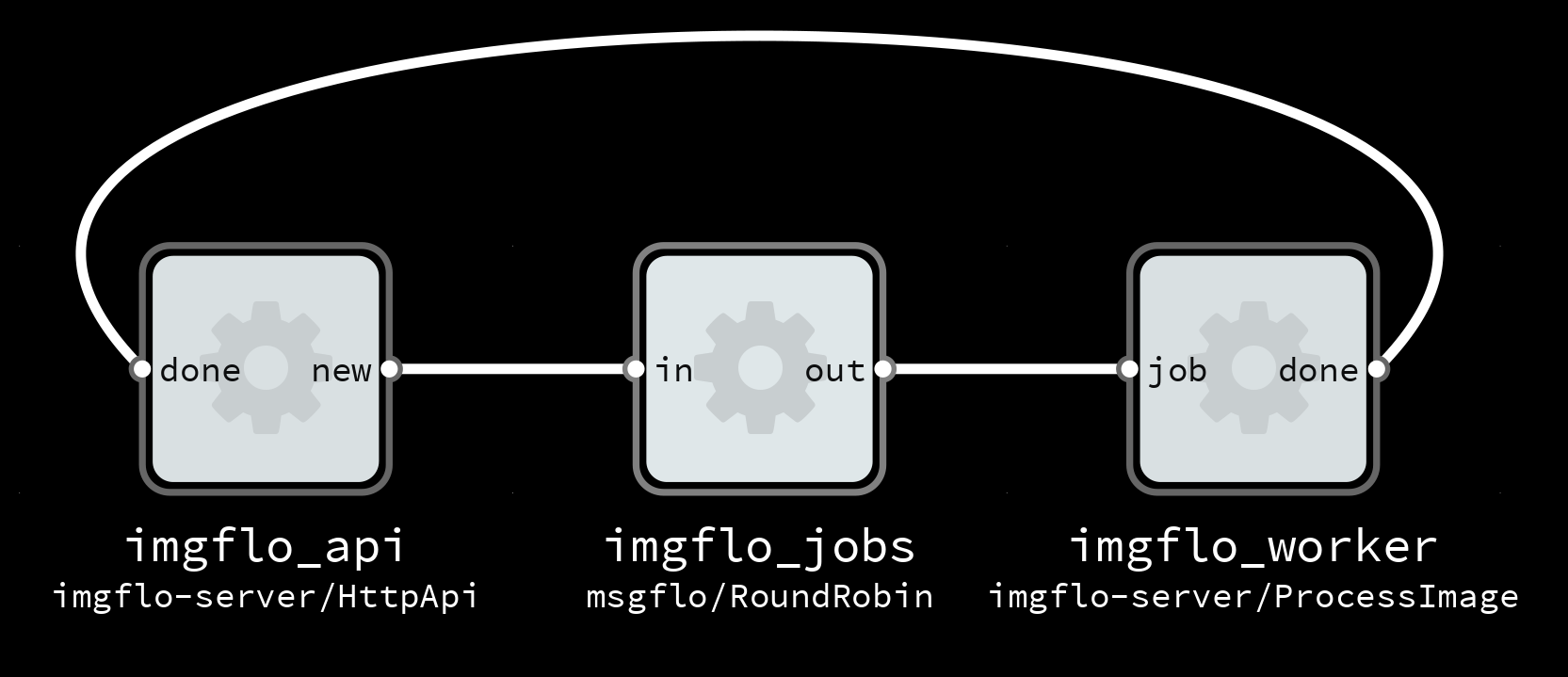
All computationally intensive work is put as jobs in a AMQP/RabbitMQ message queue, which are consumed by Heroku workers. To make it easy to manage many queues and worker roles we also use MsgFlo.
This provides us with the required flexibility to scale: the queues buffer the in-progress work, broker distributes evenly between available workers, and with Heroku we can change number of workers with one command. But, it still leaves us with the decision on how much compute capacity to provision. And when load is dynamic, it is tedious & inefficient to do it manually – especially as Heroku bills workers used by the second.
Monitoring RabbitMQ queues and scaling Heroku workers manually when demand changes; not fun.
If we would instead regulate this every 1-5 minute based on demand, we would reduce costs. Or alternatively, with a fixed budget, provide a better quality-of-service. And most importantly, let developers worry about other things.
Of course, there already exists a number of solutions for this. However, some used particular metrics providers which we were not using, some used metrics with unclear relationship to required workers (like number of users), or had unacceptable limitations (only one worker per service, only run as a service with pay-by-number-of-workers).
guv
guv 0.1 implements a simple proportional scaling model. Based the current number of jobs in the queue, and an estimate of job processing time – it calculates the number of workers required for all work to be completed within a configured deadline.
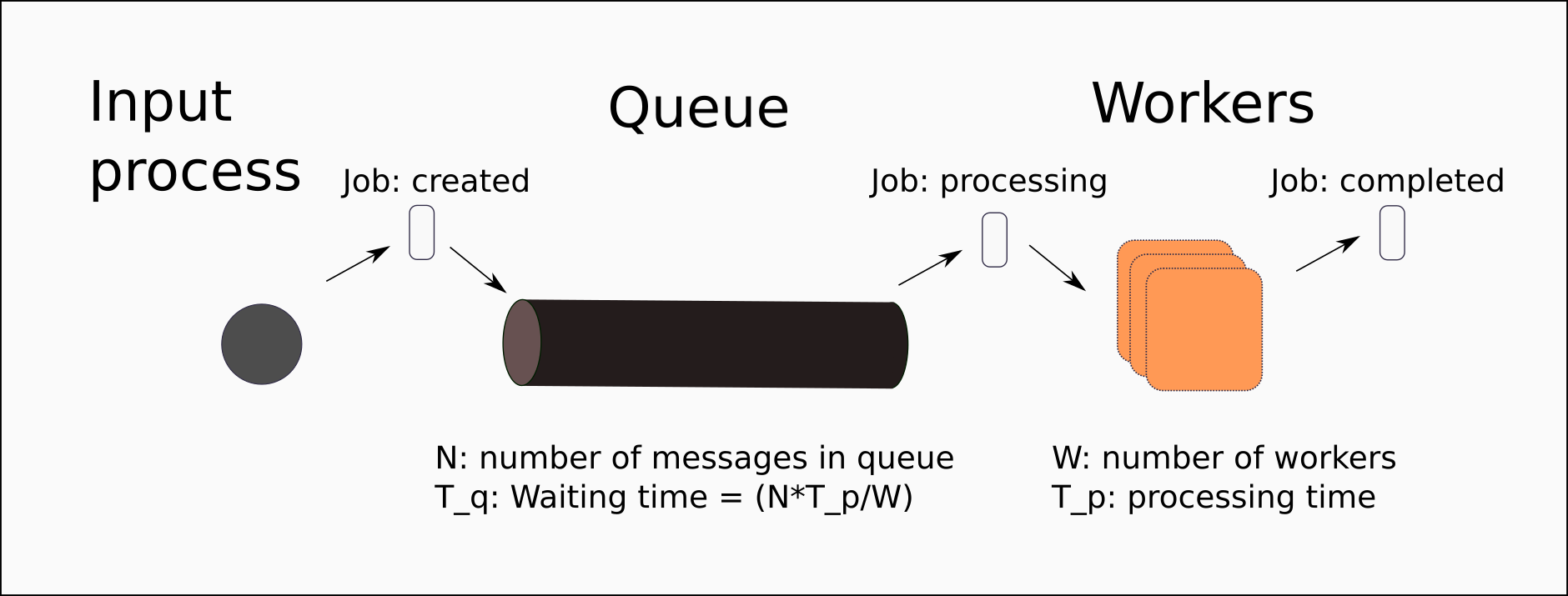
The deadline is the maximum time you allow for your users to wait for a completed job. The job processing time [average, deviation] can be calculated from metrics of previous jobs. And the number of jobs in queue is read directly from RabbitMQ.
# A simple guv config for one worker role.
# One guv instance typically manages many worker roles
'*':
app: my-heroku-app
analyze:
queue: 'analyze.IN' # RabbitMQ queue name
worker: analyzeworker # Heroku dyno role name
process: 20
deadline: 120.0
min: 1 # keep something always running
max: 15 # budget limits
Now there are a couple limitations of this model. Primarily, it is completely reactive; we do not attempt to predict how traffic will develop in the future. Prediction is after all terribly tricky business – better not go there if it can be avoided.
And since it takes a non-zero amount of time to spin up a new worker (about 45-60 seconds), on a sudden spike in demand may cause some jobs to miss a tight deadline, as the workers can’t spin up fast enough. To compensate for this, there is some simple hysteresis: scale up more aggressively, and scale down a bit reluctanctly – we might need the workers next couple of minutes.
As a bonus, guv includes some integration with common metrics services: The statuspage.io metrics about ‘jobs-in-flight’ on status.thegrid.io, come directly from guv. And using New Relic Insights, we can analyze how the scaling is performing.
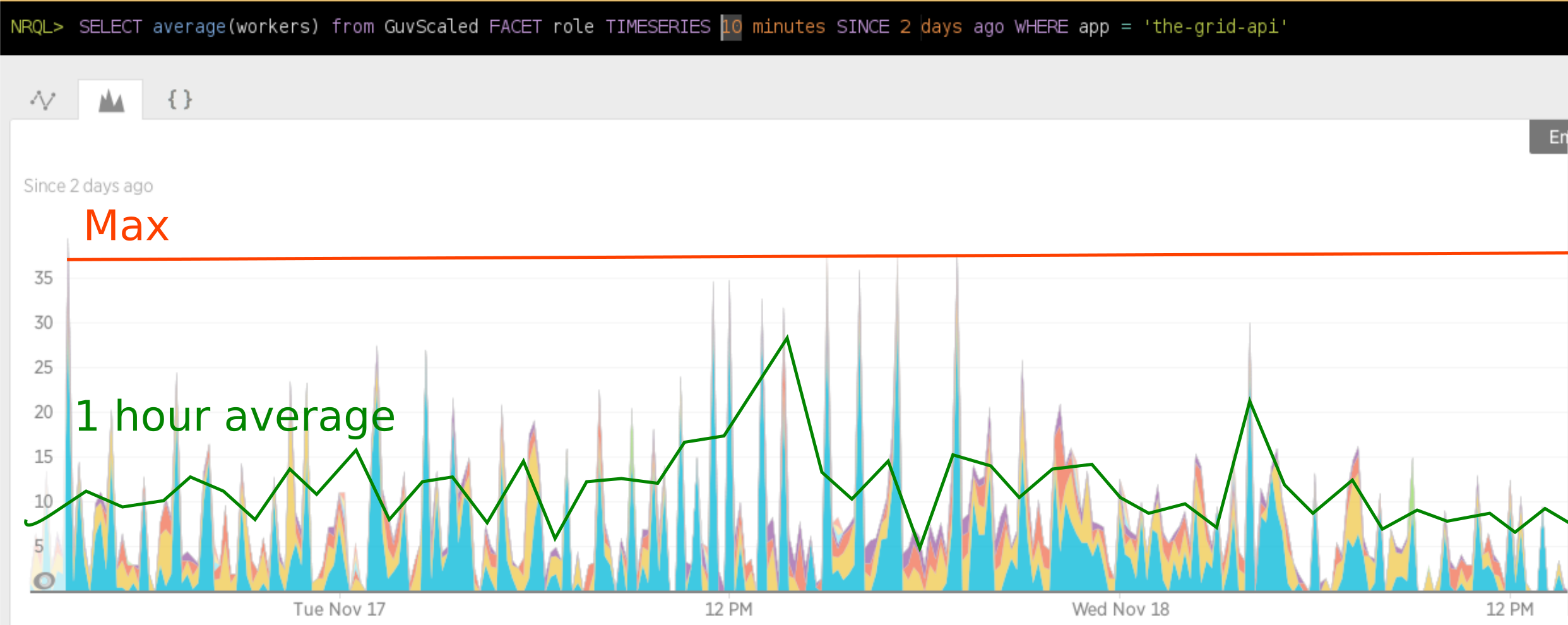
Last 2 days of guv scaling history on some of the workers roles at The Grid.
If we had a manual scaling with a constant number over 48 hours period, workers=35 (Max), then we would have paid at least 3-4 times more than we did with autoscaling (difference in size of area under Max versus area under the 10 minute line). Alternatively we could have provisioned a lower number of workers, but then with spikes above that number – our users would have suffered because things would be taking longer than normal.
We’ve been running this in production since early June. Back then we had 25 users, where as now we have several thousand. Apart from updating the configuration to reflect service changes we do not deal with scaling – the minute to minute decisions are all done by guv. Not much is planned in terms of new features for guv, apart from some more tools to analyze configuration. For more info on using guv, see the README.