Back in 2018, during my master in Data Science, I started the emlearn project – implementing classic Machine Learning models designed to run on microcontrollers and embedded devices (aka “TinyML”). Back then, the primary purpose was to learn the ins and outs of these algorithms, to make sure I really understood them well. Thinking about how the algorithms can be implemented efficiently in terms of RAM usage, storage space and CPU time is excellent for that purpose. But I always made sure to keep the code at production-quality, with a decent set of automated tests.
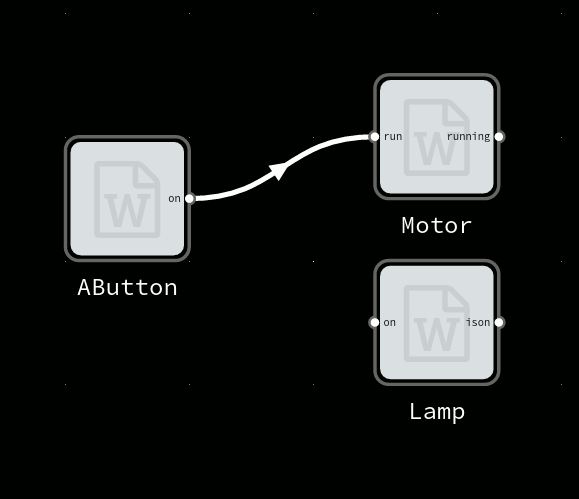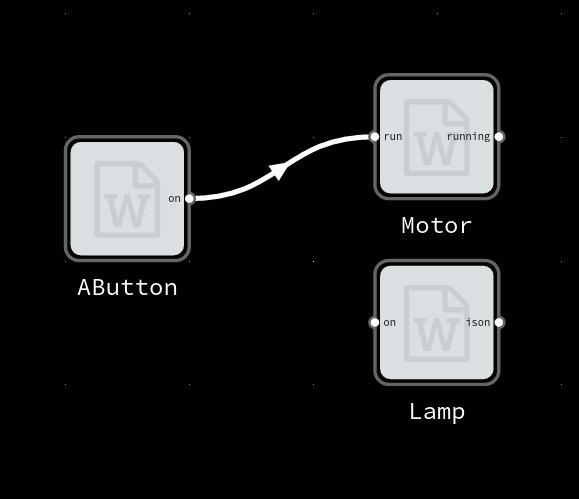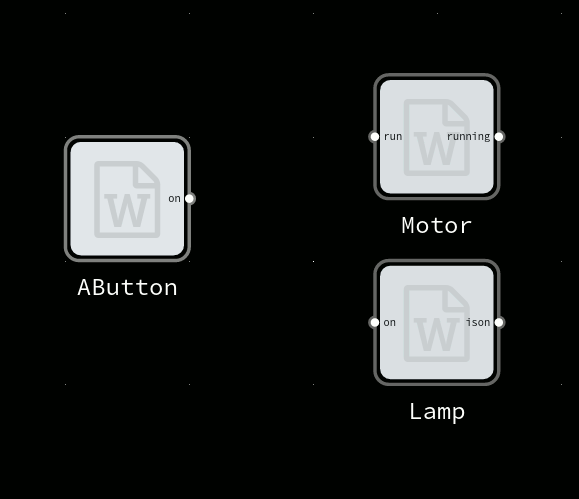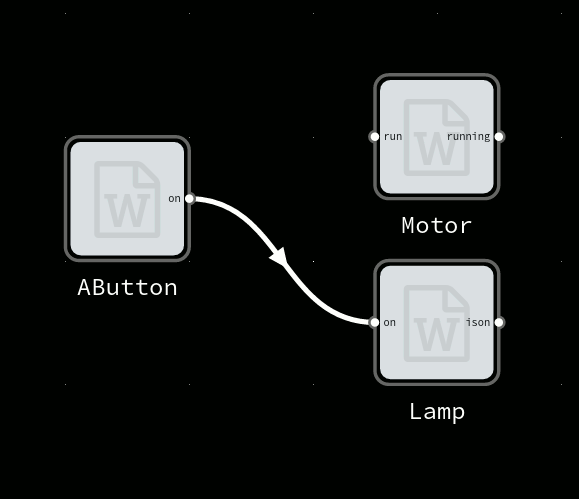
emlearn in use
Fast-forward 5 years, and emlearn has actually been used in a wide range of real-world projects, which is fantastic. Due to the open-source nature, everyone can just download it and use it for whatever they want – so there are probably many uses we will never hear about. And that is fine 🙂 But, there are some uses that I do know of. So here is a small selection of some of the projects using emlearn.
These projects highlight some of the typical characteristics for projects where emlearn is a good fit. Sensor data is analyzed on-device using a combination of Digital Signal Processing and Machine Learning. The extracted information is a low rate data-stream which can then be transmitted wirelessly. All of this can be done on low-cost hardware using general-purpose microcontrollers. Many tasks can also be done at low-power and run on battery.
Researchers from Sandia National Laboratories developed a system to identify the origin of faults in the power grid. When an abrupt fault occurs in a power transmission line, this causes a wave that propagates along the line. The wave is influenced by the electrical characteristics of the line as it travels along to other locations in the grid. The researchers used a combination of Digital Signal Progressing and Random Forest classifier to analyzes the signature of an incoming wave, and determines where the fault originated. They tested the system by injecting faults in a simulated model of a grid, and then ported the procedure to a DSP board from Texas Instruments.
Being able to automatically locate failures that occur in grid power lines is key to being able to dispatch maintenance crews to the right place, and could enable quicker recovery times after failures.
Researchers at Samsung used a combination of motion data from the accelerometer and sound data from the microphone on Samsung Galaxy earbuds to estimate breathing rate. First, breathing rate estimation is attempted using the accelerometer. If no estimation can be made, then the audio microphone data is used to estimate breathing rate. This multi-modal approach handles a wide range of cases, which they tested both in a laboratory and home setting. The battery consumption was low enough that the measurements could run continuously.
This kind of technology could be especially useful for people with respiratory diseases, who often need to check their breathing rate to manage and quantify their lung condition.
Abhishek Damle, who was a master student at Virginia Tech in 2022, developed a battery-powered sensor that tracks cattle activity. The sensor is mounted on the cow’s halter, and uses a low-power accelerometer to sense motion. A decision tree is used to classify whether the cow is lying/walking/standing/grazing/ruminating. The detected activity is then transmitted LoRaWAN to a central location. They estimate that doing the machine learning on-sensor it consumes under 1 mW, which is 50 times less than if transmitting the raw data.
The activity data can be used to detect abnormal behavior in a cow, which can indicate health issues or other problems.
Recent developments
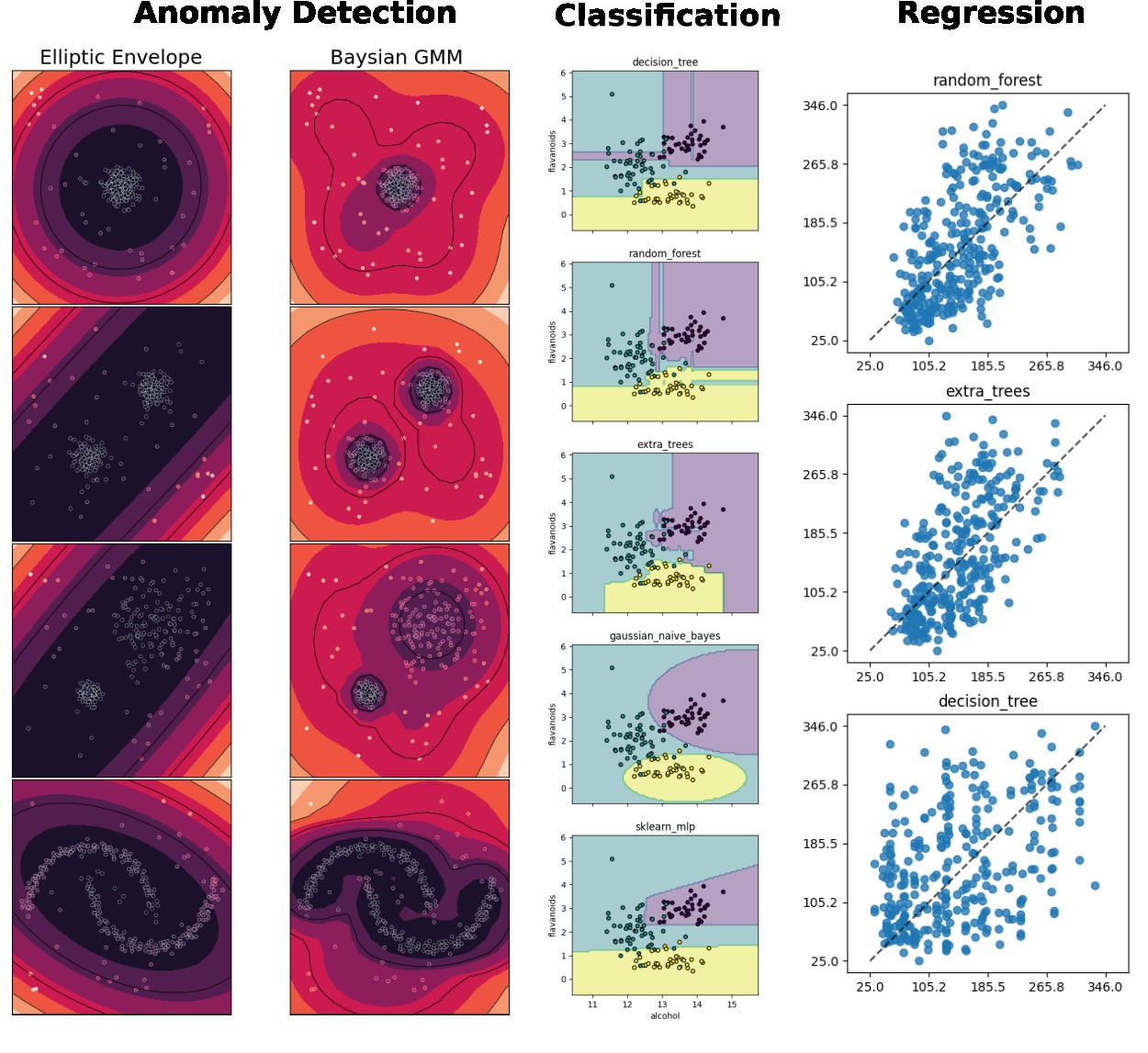
Classification, regression and anomaly detection
emlearn allows converting scikit-learn and Keras models trained in Python into efficient and portable C code. The first versions of only supported classification. Over the last years, we have also added support for regression and anomaly/outlier detection for a range of models.
Examples of outputs for some of the models supported by emlearn, in different types of ML tasks
Improved documentation
To facilitate further usage, I decided to do a pass to improve the documentation this summer. Now there is more detailed documentation for Getting Started, that covers setting up and running the first model – be it on your PC, on Arduino, or running in a Web browser. There are also task-oriented pages in the user-guide – covering Classification, Regression, Anomaly Detection, Event Detection (for now).
emlearn documentation now has a User Guide, C API reference, Python API reference and Examples
MicroPython support
Whereas C is the lingua franca for embedded/firmware engineers, Python is the lingua franca for Data Scientists and Machine Learning Engineers. emlearn itself is written in portable C99, and makes it easy to train in Python (on computer) and deploy to C (on device). This is practical, but for some users and applications it could be even nicer to do also the device code in Python. This is now made easy with emlearn-micropython.
The MicroPython project is a Python (3.x) implementation designed for microcontrollers. It is around 10 years old by now, and has a good level of maturity. It is a very efficient and compact Python implementation, and runs on 32-bit devices with at least 256k of code space and 16k of RAM.
The emlearn-micropython are released as .mpy modules, which can be added to an existing board by copying it over USB/serial/WiFi. No rebuilding or flashing of the firmware needed! This uses the dynamic native modules feature in MicroPython. This is really quite magical, and lets us realize a workflow which has the convenience of Python, and the efficiency of C.
Example code for host
# Train a model using scikit-learn
estimator = RandomForestClassifier(n_estimators=3, max_depth=3, max_features=2, random_state=1)
estimator.fit(X, y)
# Convert model using emlearn
cmodel = emlearn.convert(estimator, method='inline')
# Save as loadable .csv file
cmodel.save(file='xor_model.csv', name='xor', format='csv')
Example code for device
import emltrees
import array
model = emltrees.new(5, 30) # ensemble of up to 5 trees and 30 decision nodes
# Load a CSV file with the model
with open('xor_model.csv', 'r') as f:
emltrees.load_model(model, f)
# run inference with the model
examples = [
array.array('f', [0.0, 0.0]),
array.array('f', [1.0, 1.0]),
array.array('f', [0.0, 1.0]),
array.array('f', [1.0, 0.0]),
]
for ex in examples:
result = model.predict(ex)
print(ex, result)
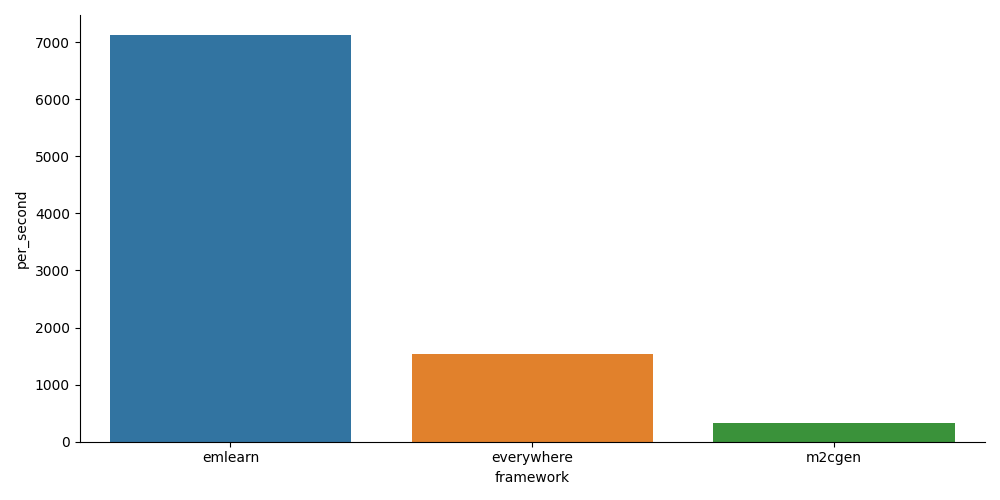
There are some existing projects that allow to generate (Micro)Python code for ML models, such as m2cgen and everywhereml. But while MicroPython is a pretty efficient Python, a C implementation should still be able to do better. To test this, I ran some quick benchmarks. These were performed on a RP2040, an affordable and popular ARM Cortex M0 chip.
Inference speed comparison of emlearn-micropython compared to other frameworks. Y axis is the number of samples per second (higher is better).
As expected, the emlearn approach is many times faster than pure-Python based approaches. This could be further increased by enabling fixed-point/integer support in emlearn.
The TinyML wave has only just begun
emlearn is a library for Machine Learning on microcontrollers and embedded systems – often referred to as TinyML. There are over 20 billion microcontrollers shipped every year. From 2022 it is estimated that over 2 billion of these are TinyML devices, up from 15 million in 2019[1]. So it is still very early days for this field. And it will be very interesting to see where emlearn goes in the next 5 years.
At EuroPython 2019 in Basel I gave an introduction to the use of modern machine learning for audio classification. It was very well received, both at the event and the video recording afterwards. The full video recording can be found here (YouTube).
Below I provide a transcript of the presentation, for those who prefer to read instead of looking at a video.
Introduction
[chair]
Welcome to the session.
Jon Nordby is a maker and full-stack IoT developer.
He successfully defended his master’s thesis in Data Science two weeks ago and he’s now embarked on an IoT startup called Soundsensing.
Today he’ll talk to us about a topic related to his thesis: Audio classification with machine learning.
[presenter]
Hi thank you.
So, audio classification is not such a popular topic as for instance image classification or a natural language processing.
So I’m happy to see that there’s still people in the room and interested in this topic.
About me
So first a little about me. I’m an Internet of Things specialist.
Have background in electronics from nine years ago.
Worked a lot as a software engineer, because electronics is mostly software these days or a lot of software.
And then I went to do a Masters in Data Science because IoT to me is the combination of
electronics (sensors especially),
software (you need to process the data),
and data itself – transform sensor data into information that is useful.
Now I’m consulting on IoT and machine learning and I’m also CTO of Soundsensing.
We deliver sensor units for noise monitoring.
About the talk
In this talk my goal (we’ll see if we get there), is that you as a machine learning practitioner, without necessarily prior experience in sound processing, can solve a basic Audio Classification problem.
We’ll have an introduction about digital sound very briefly.
And then we’ll go through a basic audio classification pipeline.
And then some tips and tricks for how to kind of go little bit beyond that basic.
And then I’ll give some pointers to more information.
The slides and a lot of my notes on machine hearing, in general little bit broader than audio classification, is on this github: https://github.com/jonnor/machinehearing/
Applications
There are some very well recognized subfields of audio, speech recognition is one of them.
And for instance there you have as a classification task you have keyword spotting, so: "Hey Siri" or "OK Google".
And in music analysis you also have many tasks, genre classification for instance can be seen as a simple audio classification task.
We’re gonna keep it mostly on the general levels: we’re not gonna use a lot of speech or music specific domain knowledge.
We still have examples across a wide range of things, I mean anything you can do with hearing as a human you we can get close to (on many tasks at least) with machines today.
In ecoacoustics you might wanna analyze bird migrations using sensor data to see their patterns.
Or you might want to detect poachers in protected areas to make sure that no one actually is going around shooting where there should be no gunshots.
It’s used in quality control in manufacturing. Especially because you don’t have to go into the equipment or the product under test, you can listen it to it from the outside.
For instance used for testing your electrical car seats they check that all motors run correctly.
In security it’s used to help monitor large amounts of CCTVs by also analyzing audio.
And in medical for instance you could detect heart murmurs which could be indicative of a heart condition.
Background
Digital sound
First thing to that is important is that sound is almost always, or basically always, a mixture.
Because sound, I mean, it will move around the corner, unlike image for instance.
And you will always have sound coming from multiple placee.
It will also transport in the ground and be reflected by a wall.
And all these things makes it so you always have multiple sound sources:
The source of interest and then always other sound sources (noise).
Audio Aquisition
Physically we have a sound as its variation in air pressure.
We go through a microphone to converted to electrical voltage,
an Analog-to-Digital converted (ADC) and then we have a digital waveform – which is what we will deal with.
As digital audio, it’s quantized in time for instance with the sampling rate and amplitude.
We usually deal with mono primarily with one channel when we do Audio Classification.
There are some methods around stereo but not widely adopted, and also more channels.
We typically use uncompressed formats, it’s just the safest.
Although you in real life situation you might also have compressed data,
which can have artifacts and so on that might influence your model.
Spectrograms
So after we have a waveform we can convert it in a spectrogram.
And this is in practice a very useful representation,
both as a human for understanding (what is this sound) and for the machines.
To use this one example, is a frog croaking like / r / r / r.
Very periodically, with a little gap.
And then it’s hard to see but in top in a higher level there is some cicadas that are going as well.
This allows us to both see the few frequency representation and the patterns across time.
And together often this allows you to separate different sound sources from your mixture.
Environmental Sound Classification
So we’ll go through a practical example just to keep it kind of hands-on. Environmental Sound Classification.
Given a signal of environmental sounds, these are everyday sounds that are around in the environment.
For instance it can be out outdoors: Cars, children and so on.
It’s very widely researched. We have several open data sets that are quite good. AudioSet is several I think tens of thousands or even hundreds of thousands of samples.
And in 2017 we’ve reached roughly human level performance (only one of these data sets, ESC-50 , has an estimate for what is human level performance) but we seem to have surpassed enough.
Urbansound8k dataset
And one nice data set is the Urbansound8k which has ten classes of 8k samples.
They’re roughly 4 seconds long and 9 hours total and state of the art here is around 80 percent (79 to 82) of accuracy.
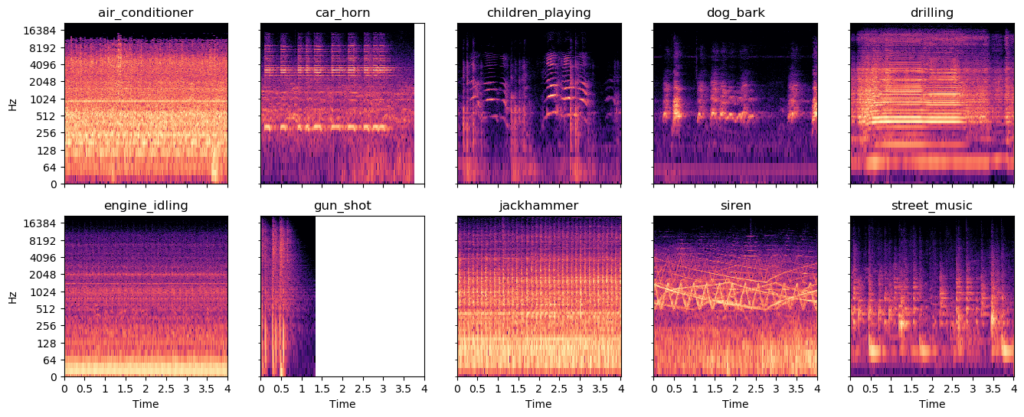
Here we have some spectrograms and these are the easy samples.
This data set has many challenging samples where the sound of interest is very far away and hard to detect, and these ones are easy.
So you see the siren goes like very up and down and jackhammers and drilling have very periodic patterns.
So how can we detect this using a machine learning algorithm in order to output these classes?
A simple Audio Classification pipeline
I will go through a basic audio pipeline, and skipping around like 30 to 100 years of history of audio processing, kind of going straight to what is now the typical way of doing things.
And it looks something like this.
Overview
So first in the input we have our audio stream.
It’s important to realize that of course audio has time related to it so it’s more like a video than to an image.
And in practical case scenario might you do real-time classification so this might be a infinite stream that just goes on and on.
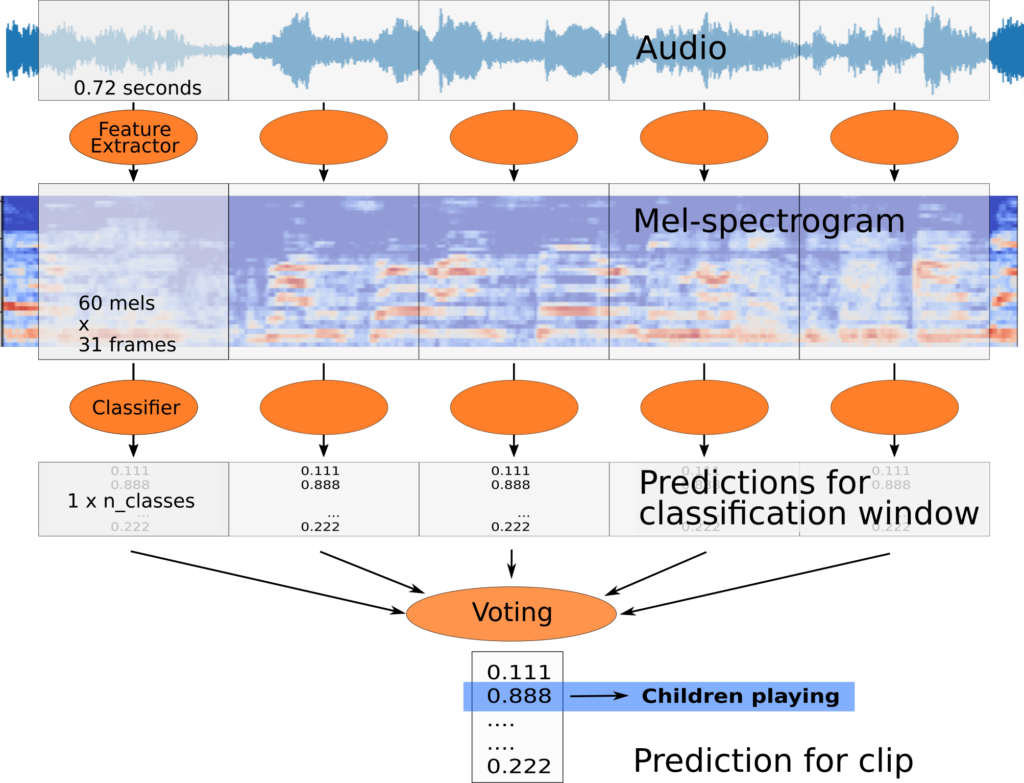
So it’s important for that reason and for also the Machine Learning to divide the stream into small or relatively small analysis windows that you will actually process.
However you often have the mismatch between how often you have labels for your data versus how often you actually want a prediction.
This is known as weak labeling.
I won’t go much into it but so in the Urbansound8k it’s for sound 4 seconds sound snippet so that’s what kind of are we’re given and this curated data set.
However it’s usually beneficial to use smaller analysis windows to reduce the dimensionality of the machine learning algorithm.
So the process goes that we will divide the audio into these segments, it will often use overlap.
And then we’ll convert it into a spectrogram and we’ll use a particular type of spectrogram called a Mel-spectrogram which been shown to work well.
And then we’ll pass that frame or features from the spectrogram into our classifier and it will output the classification for that small time window.
And then because we have labels per 4 seconds we’ll need to do an aggregation in order to come up with the final prediction for these four seconds, not just for this one little window.
Yeah we’ll go through these steps now.
Overlap of analysis windows
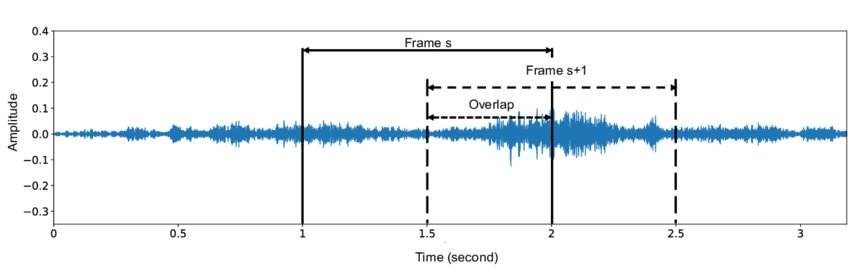
So first analysis we notice I mention we often use overlap.
Overlap is sometimes specified in two different ways: one is an overlap percentage.
Here we have 50% overlap, so that means that we’re essentially classifying parts of the or we’re classifying every piece of the other stream twice.
So we could have even more overlap people maybe a 90 percent overlap then we’re classifying it 10 times.
And that gives the algorithm multiple viewpoints on this audio stream, and makes it easier to catch the sounds of interest.
Because the model might in training, might have learned to prefer a certain sound to appear in a certain position inside this analysis window.
Overlap is a good way of of working with that.
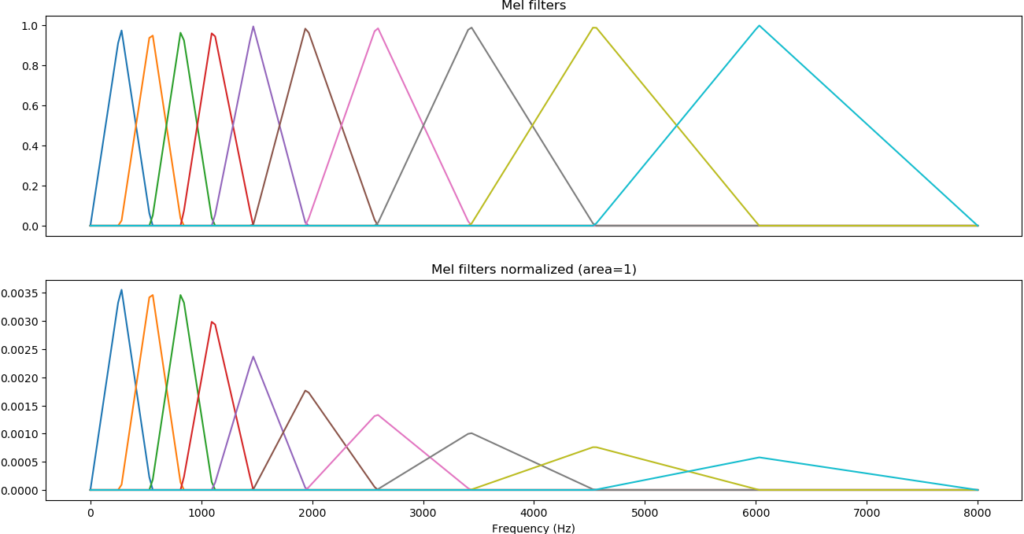
Mel-spectrograms preprocessing
so a mission we used a specific type of spectrogram.
So the spectrogram is usually processed with those called Mel-scale filters these are inspired by the human hearing.
Our ability to differentiate sounds of different frequencies reduce is reduced as frequencies to get higher.
So low sounds were able to detect small frequency of variations however high pitched sounds we need large frequency variations towards.
And by using this kind of filters on the spectrogram we obtain the representation is some more similar to our ears.
But more importantly it’s a smaller representation for a machine learning model, and also you’ll be able to merge kind of related data in in two consecutive bins for instance.
So when you’ve done that it looks something like this.
On the top is a normal spectrogram and you see kind of a lot of small details.
The bottom one we’ve we started the Mel filters at 1000 Hertz.
This is bird audios which is quite high pitched, a lot of chirps up and down.
And in the third one we’ve with normalized the earth.
We usually use log-scale compression because sound has a very large dynamic range.
So sounds that are faint versus sounds that are very loud for the human ear is a factor of 1000 or a factor of 10,000 in energy difference.
So when you’ve normalized log-scaled applied the spectrum and normalized you look at something like the image below.
So in Python code this picture shows the processing.
I’m not gonna go through all this in detail, we have an excellent library called librosa which is great for just loading and loading the data and doing basic feature pre-processing.
Also some of the deep learning frameworks have their own Mel-spectrogram implementations that you may also.
Normalizing across sample or window
But there is a general thing in streaming.
So when people analyze audio they often apply normalization learned from the mean for instance across their whole samples for four seconds in this case, or from their whole data set.
That can be hard to to apply when you have a continuous audio stream which has for instance changing volume and so on.
So what we usually do is to normalized per frame so the hope is that you have enough information in our roughly one second of the data in order to do a this normalization.
And doing normalization like this has some interesting consequences when there is no input.
Because what happens is if you have no input to your system, probably you’re gonna blow up all the noise.
So your sometimes need to exclude very low energy signals from being classified.
Just like little practical tip.
Convolutional Neural Network
So Convolutional Neural Networks, they’re hot.
Who here has basic familiarity, at least gone through a tutorial or read a blog post about image classification and CNN’s?
Yeah that’s quite a few.
So CNN’s are the best in class for image classifications.
Spectrograms are image-like audio representation, they have some differences, so a question is (or maybe it was): will CNN’s work well on spectrograms?
Because that would be interesting and the answer is… yes.
This been researched quite a lot, and this is great because there is a lot of tools, knowledge, experience and pre-trained models for image classification.
So being able to reuse those in the audio domain, which is not such a big field, is a major major win.
So you’ll see a lot of the research lately is, it can be a little bit boring in audio classification research, because a lot of it is like taking one year ago image classifying tools and applying them, and seeing whether it works.
It is however a little bit surprising that this actually works because the spectrogram has frequency on the y-axis (typically it’s shown that way) and time on the other axis.
So a movement or a scaling in this space doesn’t mean the same as in an image.
You know an image if I have my face inside an image doesn’t matter where my face appears.
If you have a spectrogram and you have certain sound it’s like a chirp up and down, if you move that up in frequency or down, at least if you move it a lot, it’s probably not the same sound anymore.
It might go from a human talking to a bird, the shape might be similar but the position matters.
So it’s a little bit surprising that this works, but it does seem to do really well in practice.
SB-CNN
So this is one model that does well on Urbansound.
And one thing you’ll note compared to a lot of image models is that it’s quite simple, I mean relatively few layers. This is smaller than or the same kinda size as LeNet5.
And there are three convolutional blocks followed by Mike and with max pooling between the two first blocks.
And that’s, you know, the standard kind of CNN architecture.
This one using five by five instead of two or three kernels, doesn’t make much of a difference you could stack another layer and do the same thing.
And we flatten and then we use a fully connected layer.
From 2016 and still is one is like close to state-of-the-art on this dataset, Urbansound8k.
If you are training CNN from scratch on audio data, start with a simple model.
I mean there’s no usually no reason to start with say VGG16 with 16 layers and millions of parameters,
or even MobileNet or something like that.
You can usually go quite far with with this kind of simple architecture – a couple of convolutional layers.
So in case for example this could look something like this.
Where we have our individual kind of blocks. Convolution, Maxpooling, ReLu non-linearity.
Same for the second one and our full classification at the end the full connected layers.
So this is our classifier.
We will pass the spectrogram analysis window through this,
and it will give us a prediction for which class it was among the classes in Urbansound.
Aggregating analysis windows
And then we need to aggregate these individual windows, and there are multiple ways of doing this.
You could do simplest kind of thing to think about is to do majority voting.
So if we have ten windows over four second spectrum we could do the predictions,
and then just say okay the majority (most common) class wins. That works rather well.
But it’s not differentiable, and so it is done as post-processing.
And you’re making very rough predictions on each on a step.
So mean mean pooling or global average pooling across those analysis windows usually does a little bit better.
And it’s nice with deep learning frameworks is that you can also have this as a layer so for instance in Keras you have the TimeDistributed layer.
Which is there’s sadly extremely a few examples of online.
It’s not that hard to use but it took me a while it to to figure out how they do it.
So we apply a base model, which is in this case the input to this function.
We pass it to the TimeDistributed layer and which essentially it will use a single instance of your model, so it’ll share the weights for all these steps for all the analysis windows.
And then it will just run in multiple times when you do the prediction step and then it will global average pooling over these predictions.
So here we’re averaging predictions you can also you can also do more advanced things where you would for instance average your feature representation and then do a more advanced classifier on top of this.
But this was called probabilistic voting quite often in literature, when you do this mean pooling.
That allows us so this will give us a new model which is what will take not single in analysis windows, which will take a set of analysis windows typically corresponding to our 4 seconds with for example 10 windows.
Demo
So if you do this and a couple more tricks from my thesis you can have a system working like this demo.
So this has, in addition to building model and so on which I’ve gone through,
we’re also deploying to a small microcontroller using the vendor provided tools that converts a Keras model.
And so that’s kind of roughly standard things, so I don’t go into it here.
So little demo video (if we have sound).
Here is Children playing.
Thing is basically what we do also here is we threshold the prediction. So if no prediction is good we’ll consider it unknown.
And this is also important in practice because sometimes you have out of class data.
This is Drilling.
Or this actually the the sample I found said jackhammer. Jackhammer is actually another class.
And really they are to my ear hard to distinguish sometimes and the model can also struggle with it.
There is Dog Barking.
And so in this case all the classification happens on the small sensor unit which is what I focused on in my thesis.
Siren
The model actually it didn’t get the first part of the siren. Only the undulating part later.
So actually these samples are not from the Urbansound dataset which I’ve trained out.
So they’re "out of domain" samples, which is generally a much more challenging.
Yes that’s it for demo.
If you want to know more about doing sound classifications on these sensor units you can get my full thesis.
Both the report and the code is there.
Tips & Trick
Some tips and tricks.
So we’ve covered the basic audio processing pipeline, the modern one, and that will give you results and generally quite good results with the modern CNN architecture.
And there are some tips and tricks especially in practice where when you are having a new problem:
You’re not researching an existing data set, your data sets are usually much smaller and it’s quite costly and tedious to annotate all the data
And so here are some tricks for that.
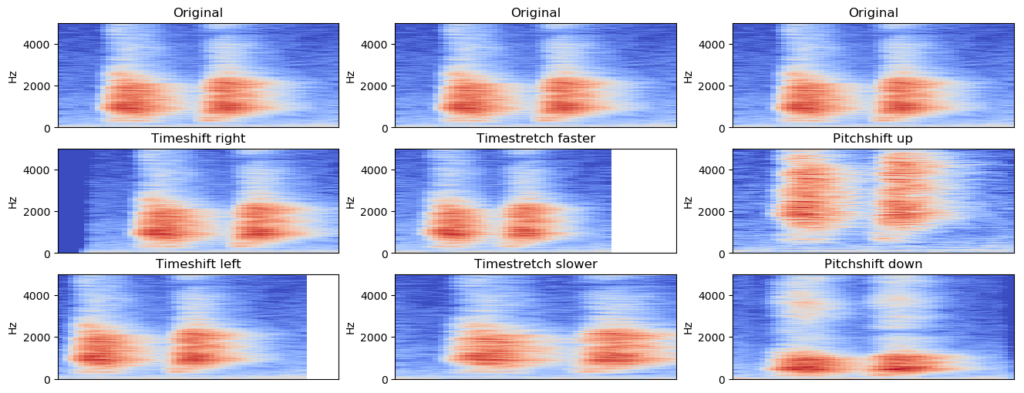
Data Augmentation
First one is data augmentation.
This is well known from from other deep learning applications, especially image processing.
And the augmentation can be done on audio can be done either in the time domain or in the spectrogram domain. And in practice it both seem to work work fine.
So here are some examples of common common augmentations.
The most common and possibly most important is to do time shifting.
So remember that I said that when you classify an analysis window we may one second you know the sounds of interest there.
And what the individual convolution kernel sees what might be very short.
If you have bird chirps they’re like and those are you know maybe 100 milliseconds max or maybe in 10 milliseconds so they they occupy very little space in that image that the classifier sees.
But it’s important that it’s able to classify classify it no matter where inside this analysis window it appears.
So time shifting simply means that you shift your samples in time forward and backward (left and right).
And that gives them you know that I would have seen that okay bird chirps can appear you know many places in time at any place in time and it doesn’t make a difference to the classification.
So this is by far the most important one and you can usually go quite far with just time shifting.
If you do want precise location of your event, so you want to have a classifier that can tell when did chirps appear.
In the 100 millisecond range instead of just that there was birds in this 4-10 seconds audio then you might not want to do time shifting.
Because you might want to have the output based on that the sound always occurs in the middle of the window.
But then you need to your labeling needs to to respect that.
Time stretching.
So many sounds you know if I speak slowly or I speak very fast its it’s the same, you know it’s the same meaning, it’s the same certainly the same class it’s both speech.
So time stretching is also very very efficient to capture such variations.
And also pitch shifting. So if if I’m speaking with low voice or a high-pitched voice you know, it’s still the same kind of information.
And the same carries in in you know for general sounds, at least a little bit, so a little bit of time shift you a pitch shift you can accept, but a lot of big shift might kind of bring you into new class.
For instance the difference between human speech and and bird chirps might be a big pitch shift.
So so you might want to limit how much you pitch shift.
Typical augmentation settings here is like maybe 10 to 20 percent on time shift and pitch.
You can also add noise.
This is also quite efficient especially if you do know that you have variable amount of noise.
Random noise works okay you can also sample.
There’s lot of repositories of basically noise, so you’ll mix in noise with your signal and classify that.
Mix-up is an interesting data augmentation strategy that makes these two samples like by a linear combination of the two and actually adjusts the labels accordingly.
And that has been shown to work really well also in combination with other augmentation techniques on the audio.
Transfer learning
So yes we can basically apply CNN’s to audio, and with the standard kind of image type architecture. This means that we can do transfer learning from image data.
So of course image data has, I mean is, significantly different from from spectrograms.
I mentioned the frequency axis and so on.
However the some of the base operations that are needed you need to detect edges you need to detect diagonals,
you need to detect patterns of edges and diagonals you need to detect kind of a blob of area.
Those are common kind of functionality needed by both.
So if you do want to use a bigger model, definitely try to use the pre-trained model.
For instance most frameworks including Keras have pretrained models on ImageNet.
The thing is that most of these models they apply take RGB color images as data.
And it can work to just like use one of those channels and zero fill the other ones.
But you can also use just copy the data and cross the three.
There’s also some paper showing that you can do multi-scale.
So for instance one has a spectrogram with very fine time resolution, and one has a one with a very coarse time resolution, and they put them in different channels. And this can be beneficial.
But because image data and some that are quite different you usually do need to fine-tune so it’s usually not enough to just apply a pre-trained model and then just tune the classifier at the end.
You do need to do a couple of layers at the end and typically also the first layer at least. Sometimes you fine-tune the whole thing, but it is generally not very beneficial.
So definitely, if you have a smaller data set, and you need that high performance, and you can’t get it with a small model – go with the pretrained model for instance MobileNet or something like that.
Audio Embeddings
Audio embeddings is another is another strategy.
Inspired by text embeddings where you create a for instance 128 dimensional vector from from your text data, you can do the same with sound.
So with "Look Listen Learn" (L3) you can convert one second audio spectrogram into 512 dimensional vector which has been trained on millions of YouTube videos, so it has seen a very large amount of different sounds and that uses a CNN under the hood. And basically gives you that that very compressed vector classification.
I didn’t finish any code sample here but there is a very nice latest work is OpenL3.
Look "Listen Learn More" is the paper, and they have a Python package which makes it super simple.
Just import, it is one function to pre-process and then you can classify audio basically just with a linear classifier from scikit-learn.
So if you don’t have any deep learning experience and you want it you want to try a Audio Classification problem definitely go this route first.
Because this will basically handle the audio part for you and you’ll just you can apply a simple simple classifier after that.
Annotating datasets
You might want to do your own dataset right. Audacity is a nice editor for for audio and it has a nice support for annotating by adding a label track.
There’s keyboard shortcuts for for all the functions that you need, so it’s quite quick to use.
So here I’m annotating some custom audio where we did event recognition
and the nice thing is that the format that they have is basically a CSV file.
It has no header and so on, but this Pandas one-liner will basically give you a nice data frame with all your annotations from the sound.
Summary
Time to summarize. We went through the basic audio pipeline.
We split the audio into fixed length analysis windows.
We used log mel-spectrogram as a sound representation because it’s shown to work very well.
We then applied a machine learning model, typically a Convolutional Neural Network.
And then we aggregated the predictions from each individual window and we merged them together using global mean pooling.
And for models I would recommend if you trying some new data,
try audio embeddings with OpenL3 and a simple model like notice fire or or random forest for instance.
Try convolutional neural network using transfer learning.
It’s quite powerful and there are usually examples that will get you pretty far.
If you do for instance preprocess spectrograms and save them as PNG files basically you can kind of take any image classification Python code that you have already.
or if you’re willing to kind of ignore this merging of different analysis windows and use that.
Data augmentation is very effective. Time-shift, time-stretch, pitch-shift, noise-add or basically recommended to use.
Sadly there is not such nice like or like go-to implementations of these in infants and Keras generators but it’s not that hard to do.
Some more learning resources for you.
The slides and also a lot of my notes in general are on this Github.
If you want a hands-on experience Tensorflow has a pretty nice tutorial called Simple Audio Recognition about recognizing speech commands.
Which could be an interesting application, but it’s taking a general approach, it’s not speech specific, so you can use it for other things.
Also there’s one book recommendation: Computational Analysis of Sound Scenes and Events.
It’s quite thorough when it comes to general audio classification. A very modern book from 2018.
Questions and Answers
Q.
Hey yeah thanks Jon, a very interesting application of machine learning. I have two questions.
So there’s obviously a like a time series component to your data, I’m not so familiar with this audio classification problem, but alright can you tell us a bit about time series methods maybe LSTM and so on how successful they are?
A.
Yes yeah time series is intuitively one would really want to apply that because there is definitely time component.
So Convolutional Recurrent Neural Networks do quite well when you’re looking at longer time scales.
For instance there’s a classification task called Audio Scene Recognition for instance.
I have a 10 or maybe 30-second clip is this from a restaurant or from a city and so on.
And there you see that the recurrent networks that do have a much stronger time modelling they do better.
But for small short tasks who CNN’s do just fine, surprisingly okay.
Q.
And the other small question I had was just to understand your label, the target that it’s learning.
You said that this is all very mixed the sound is a very mixed data set, so are the labels just like one category of sound when you’re learning,
or would it be beneficial to have you know maybe a weighted set of two categories when doing learning?
A.
Yep, so in ordinary classification tasks the typical style, or kind of by definition, is to have a single label on a some sort of window of time.
You can have multi-label datasets of course and in practice that’s a more realistic modeling of the world, because you basically always have multiple sounds.
So I think AudioSet has multi labeling and there’s a new Urbansound data set now that also has multiple labels.
And then you apply like kind of more tagging approaches.
But you’re still using classification as a base with tagging:
you can either use separate classifier per track of sound of interest,
or you can have a joint model which has multi-label classification.
So definitely this is something that you would want to do but it does complicate the problem.
Q.
You mentioned about data argumentation that we can apply Mixup to separate classes and mix them, and then the label of that mix should be weighted also because it kind of concludes with previous question usually like 0.5 and 0.5 for the other and
A.
Yes so Mixup, it was proposed things like 2-3 years ago, there’s a general method.
So you basically take your sound with your target class and you say okay let’s take 80% of that (not 100%), and then take 20% of some other sound which is a non-target class, mix it together and then update the labels accordingly.
So it’s kind of just telling you hey there is this predominant sound, but there’s also this sound in the background.
Q.
Yes you mentioned about the main frequency ranges but usually when you record audio microphones you get up to 20 thousand Hertz,
so they have you any experience or I could comment on when you have added information of the higher frequency ranges does that affect the machine learning algorithm or yeah.
A.
So typically recordings are done at 44 kilohertz or 48 kilohertz for general audio.
Often machine learning is applied at lower frequency, so with 22 kilohertz or something it is just 16, in the rare case is also 8.
So it depends on the sounds of interest if you’re doing birds definitely you want to keep that those high-frequency things.
If you’re doing speech you can do just fine on 8 kilohertz.
Usually another thing is that noise tends to be in the lower areas of the spectrum, there’s more energy in the lower end of the spectrum.
So if you are doing birds you might want to just ignore everything below 1 kilohertz for instance and that definitely simplifies your model especially if you have a small data set.
Q.
Quick question you mentioned the editor that has support for annotating audio could you please repeat the name?
A.
Yes, Audacity.
Q.
And my general question do having tips if for example you don’t have an existing dataset just starting with a bunch of audio that you want to annotate first.
Do you have any advice for strategies like some maybe semi-supervised?
A.
Yeah semi-supervised is very interesting. There’s a lot of papers but I haven’t seen like very good like practical methodology for it.
And I think in general annotating a data set is it like a whole other talk here, but I’m very interested to come to chat about this later.
Q.
Thanks to you and very nice talk.
My question would be do you have to deal with any pre-processing or like white noise filtering you mean to remove white noise,
it’s exactly just you just said like removing or ignoring certain amount?
A.
Yes, you can. I mean, scoping your frequency range definitely, it’s very easy so just do it if you if you know where your things of interests are.
Denoising. You can apply a separate denoising step beforehand and then do machine learning.
If you don’t have a lot of data, that can be very beneficial.
For instance, maybe you can use a standard denoising algorithm trained on like thousands of hours of stuff, or just a general DSP method.
If you have a lot of data then in practice the machine learning algorithm itself learns to suppress the noise.
But it only works if you have a lot of data.
Q.
So thank you for the talk.
Is it possible to train a deep convolutional neural net directly on the time domain data using a 1d convolutions and dilated convolution?
A.
Yes this is possible, and it is very actively researched.
But it’s only within the last like year or two that they’re getting to the same level of performance as spectrogram-based models.
But some models now are showing actually better performance with the end-to-end trained model
So I expect that in a couple of years maybe that will be the kind of go-to for a practical applications.
Q.
Can I do a speech recognition with this? This is only like six classes like and I think you have much more classes in speech?
A.
Yes if you want to do Automatic Speech Recognition, so the complete vocabulary of English for instance, then you can theoretically.
But there are specific models for all automatic speech recognition that will in general do better.
So if you want full speech recognition you should look at speech specific methods and there are many available.
But if you’re doing a simple task, like commands: yes/no up,down, one, two, three, four, five – you can limit your vocabulary to say maybe under a hundred classes or something, then it gets much more realistic to apply a kind of speech-unaware model like this.
Q.
Thanks for an interesting presentation.
I was just wondering from the thesis, it looks like you applied this model to a microprocessor.
Can you tell a little bit about the framework you use where you transfer it from a Python?
A.
Yes, so we use the vendor provided library from ST microelectronics for the STM32 and it’s called X-CUBE-AI.
You’ll find links in the Github.
It’s a proprietary solution, only works on that microcontroller, but it’s very simple: you throw in the Keras model, it will give you a C model out.
And they have code examples about the audio pre-processing (yeah with some bugs, but it does work).
And the firmware code for thesis is also in the Github repository, not just the model, so you can basically download that and and start going.
Over 8 years ago I completed a Bachelor in Electronics Engineering, with a focus on embedded systems. Since then I have done primarily software engineering in embedded and web projects, sometimes combined in so-called “Internet of Things” (IoT) projects. Often there was a strong data- and signal-processing focus in these systems; from audio processing in microphone-arrays, to image processing for smart website builders. Recognizing the importance of data, I realized around 2 years ago I wanted to add a new skill-set to my engineering capabilities: Data Analysis and Machine Learning (ML).
And today I’m proud to say that I have successfully completed the Master in Data Science program at the Norwegian University of Life Sciences, as one the first batch to have this degree in Norway.
Master of Data Science thesis successfully defended. Left: me, Right: External sensor Lars Erik Solheim
Research
Throughout my degree, I’ve kept the vast majority of my notes in the open-source way – public on Github. Over time I have distilled these into two resources covering the main topics of my work.
Embedded Machine Learning: Machine Learning applied to Embedded System, with a focus on-edge ML in low-cost, low-power sensors.
Machine Hearing: Using Machine Learning on audio, with a focus on general sound (less music and speech).
Thesis
My masters thesis combined these two topics, and applied it to classification of everyday urban sounds for noise monitoring in smart cities. The report and all the code can be found on Github:
Since Embedded Machine Learning is an emerging niche, the availability of software tools are not as good as for machine learning in general. To help with that I developed emlearn, an open-source ML inference engine tailored for micro-controllers and very small embedded systems. emlearn allows to convert models built with existing Python machine learning frameworks such as scikit-learn and Keras, and execute them on device using portable C code. The focus is on simple and efficient models such as Random Forests, Decision Trees, Naive Bayes, linear models. In this way, emlearn is a compliment to deep learning inference libraries for embedded devices, such as TFLite and X-CUBE-AI.
Consulting
While the master degree was nominally a full time program, I kept doing engineering work for customers in the period. Projects have included:
dlock. A IoT doorlock system for retrofitting existing public infrastructure doors. Developed for municipality of Oslo as part of the Oslonøkkelen project, an app that allows inhabitants to access municipality services such as libraries and recycling stations outside of manned working-hours. Made in collaboration with IoT solutions provider Trygvis IO.
Since the start of this year, I have started to focus on machine learning projects. Especially things that incorporate my particular expertise: Embedded/Edge Machine Learning, Machine Learning for Audio, and Machine Learning on IoT sensor data. The first ML consulting project for Roest coffee is well underway (details to be announced). Going forward, most of my time is dedicated to products at my new startup, Soundsensing. However, there should also be some capacity for new consulting work.
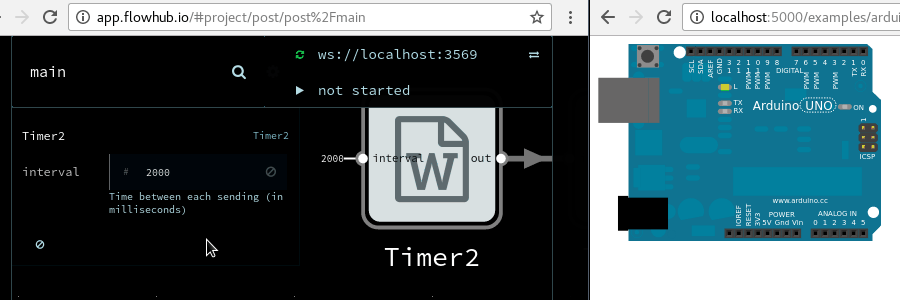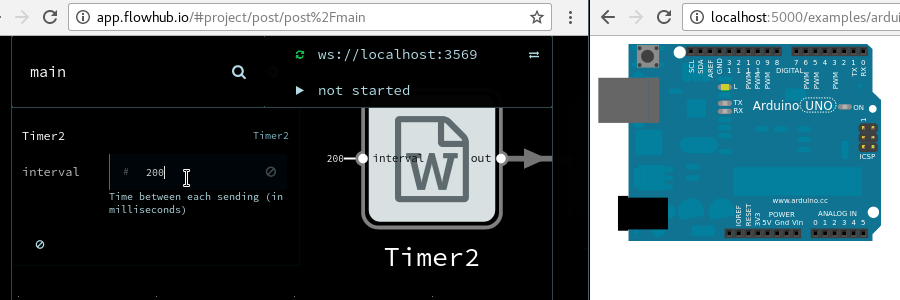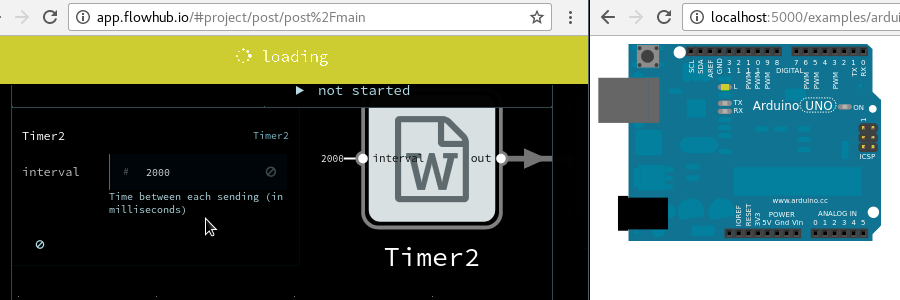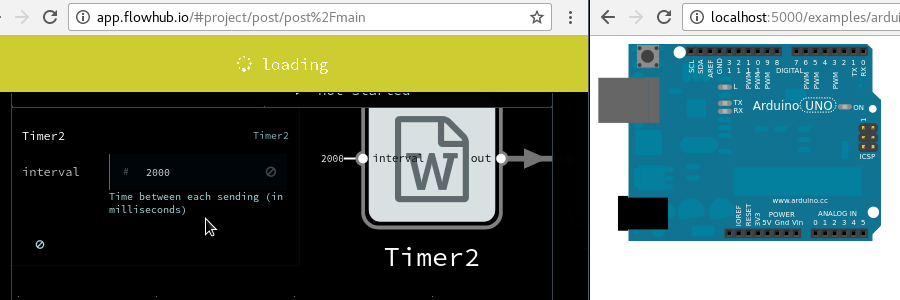
Update: The dhang is now available for preorder, and you can join a workshop to build it yourself!
Feedback from first user testing of the dhang digital hand drum was that the latency was too high. How did we bring it down to a good level?
dhang: A MIDI controller using capacitive touch sensors for triggering. An Arduino board processes the sensor data and sends MIDI notes over USB to a PC or mobile device. A synthesizer on the computer turns the notes into sound.
Testing latency
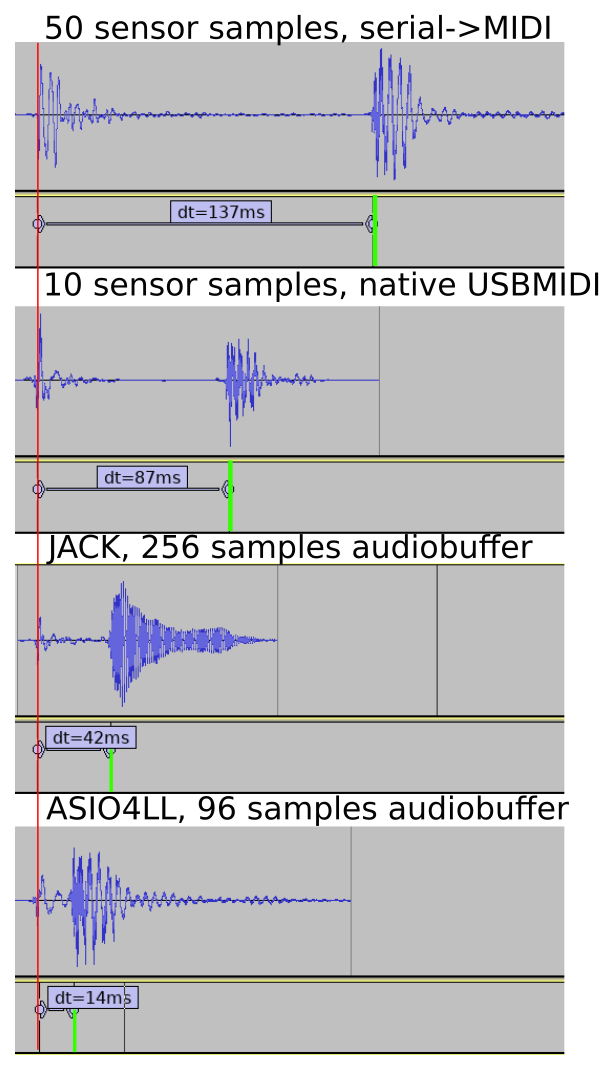
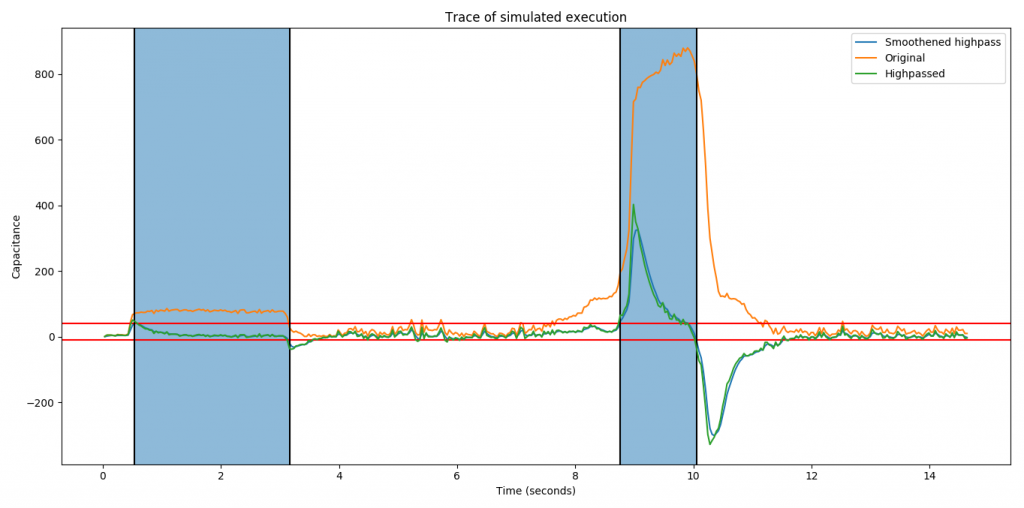
For an interactive system like this, what matters is the performance experienced by the user. For a MIDI controller that means the end-to-end latency, from hitting the pad until the sound triggered is heard. So this is what we must be able to observe in order to evaluate current performance and the impact of attempted improvements. And to have concrete, objective data to go by, we need to measure it.
My first idea was to use a high-speed camera, using the video image to determine when pad is hit and the audio to detect when sound comes from the computer. However even at 120 FPS, which some modern cameras/smartphones can do, there is 8.33 ms per frame. So to find when pad was hit with higher accuracy (1ms) would require using multiple frames and interpolating the motion between them.
Instead we decided to go with a purely audio-based method:
Test setup for measuring MIDI controller end2end latency using audio recorded with smartphone.
The microphone is positioned close to the controller pad and the output speaker
The controller pad is tapped with the finger quickly and hard enough to be audible
Volume of the output was adjusted to be roughly same level as sound of physically hitting the pad
In case the images are useful for understanding the recorded test, video is also recorded
The synthesized sound was chosen to be easily distinguished from the thud of the controller pad
To get access to more settings, the open-source OpenCamera Android app was used. Setting a low video bitrate to save space, and enabling macro-mode for focusing close objects easier. For synthesizing sounds from the MIDI signals we use LMMS, a simple but powerful digital music studio.
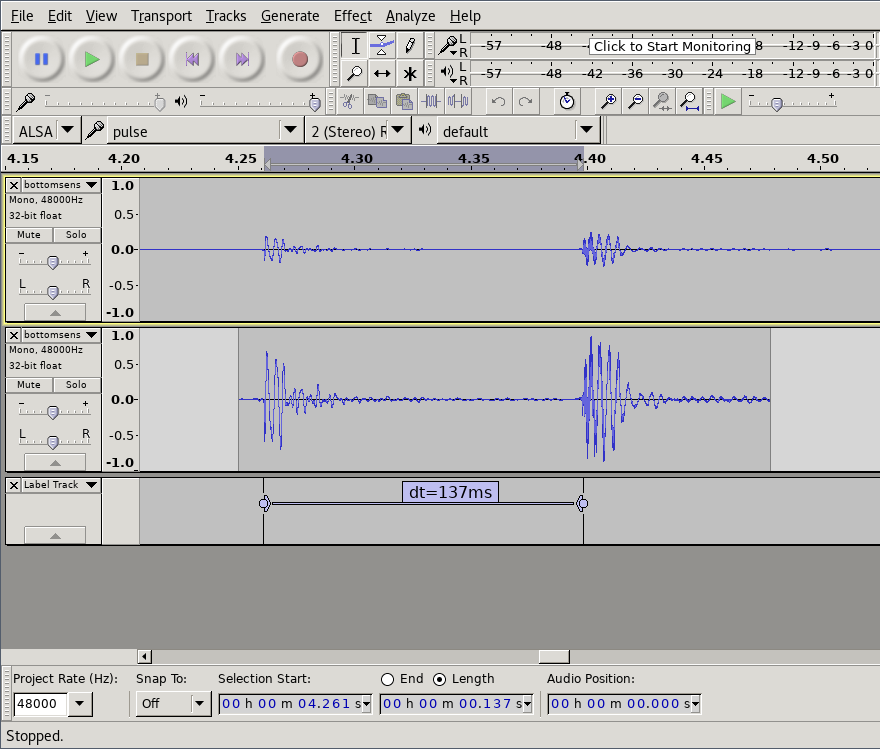
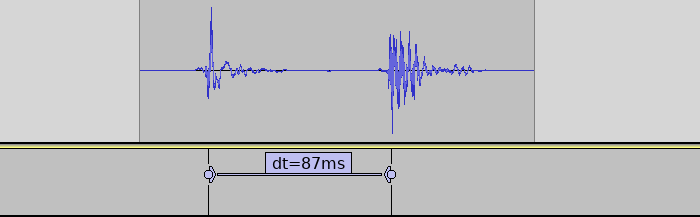
Then we open the video in Audacity audio editor to analyze the results. Using Effect->Amplify to normalize the audio to -1db makes it easier to see the waveforms. And then we can manually select and label the distance between the starting points of the sounds to get our end-to-end latency.
Raw sound data, data with normalized amplitude and measured distance between the sound of tapping the sensor and the sound coming from speakers.
How good is good enough?
We now know that the latency experienced by our testers was around 137 ms. For reference, when playing a (relatively slow) 4/4 beat at 120 beats per minute, the distance between each 16th notes is 125 ms. In the following soundclip the kickdrum is playing 4/4 and the ‘ping’ all 16 16th notes.
So the latency experienced would offset the sound by more than one 16th note! We can understand that this would make it tricky to play.
Wessel and Wright suggested that digital musical
instruments should aim for latency less than 10ms [22]
Dahl and Bresin [3] found that in a system
with latency, musicians execute their gestures ahead of the
beat to align the sound with a metronome, and that they
can maintain synchronisation this way up to 55ms latency.
Since the instrument in question is going to be a kit targeted at hobbyists/amateurs, we decided on an initial target of <30ms.
Sources of latency
Latency, like other performance issues, is a compounding problem: Each operation in the chain adds to it. However usually a large portion of the time is spent in a small parts of the system, so an important part of optimization is to locate the areas which matter (or rule out areas that don’t).
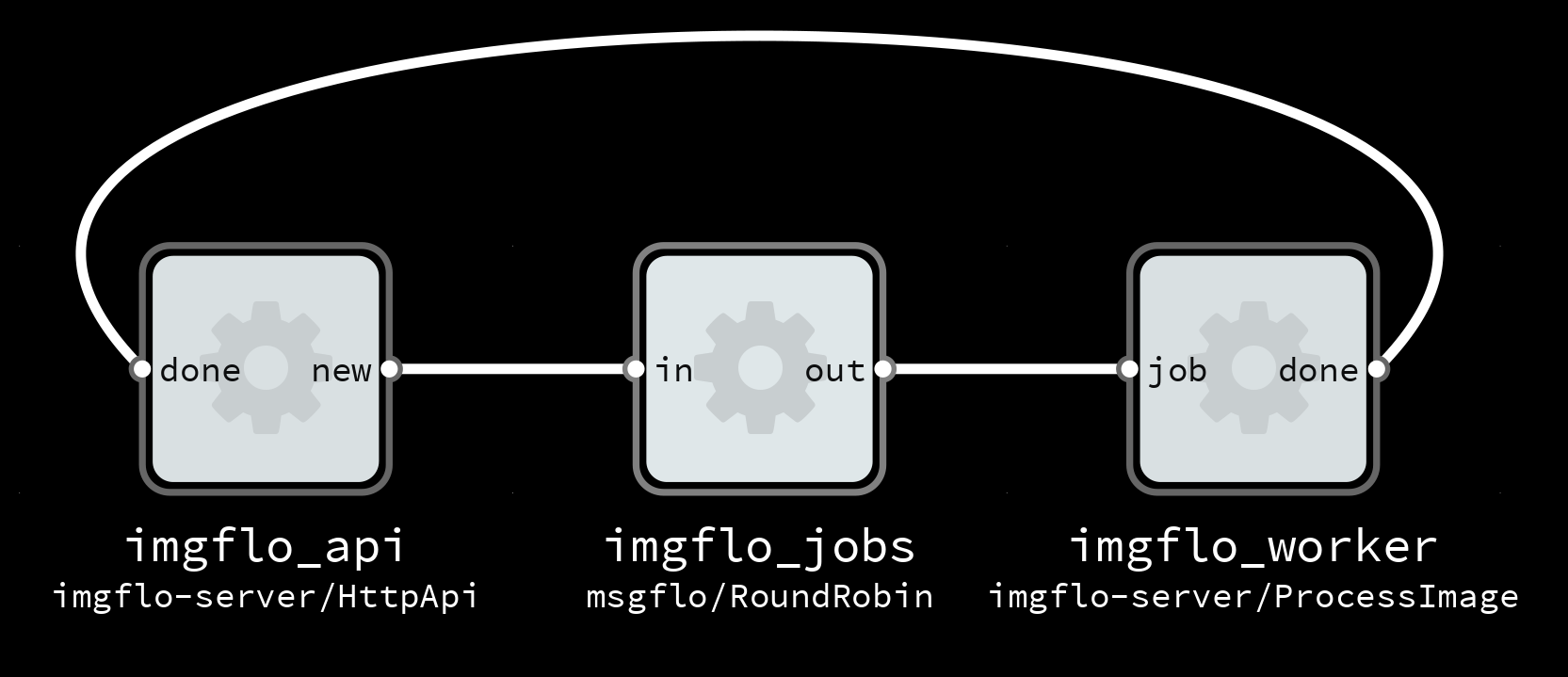
For the MIDI controller system in question, a software-centric view looks something like:
A functional view of the system and major components that may contribute to latency. Made with Flowhub
There are also sources of latency outside the software and electronics of the system. The capacitive effect that the sensor relies on will have a non-zero response time, and it takes time for sound played by the speakers to reach our ears. The latter can quickly be come significant; at 4 meters the delay is already over 10 milliseconds.
And at this time, we know what the total latency is, but don’t have information about how it is divided.
With simulation-hardened Arduino firmware
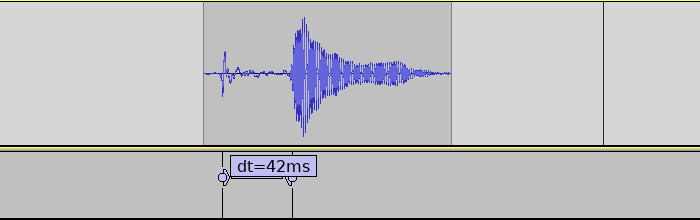
The system tested by users was running the very first hardware and firmware version. It used a an Arduino Uno. Because the Uno lacks native USB, a serial->MIDI bridge process had to run on the PC. Afterwards we developed a new firmware, guided by recorded sensor data and host-based simulation. From the data gathered we also decided to switch to a more sensitive sensor setup. And we switched to Arduino Leonardo with native USB-MIDI.
Latency with new firmware (with 1 sensor) was reduced by 50 ms (35%).
This firmware also logs how long each sensor reading cycle takes. It was under 1 ms for the recorded single-sensor setup. The sensor readings went almost instantly from low to high (1-3 cycles). So if the sensor reading and triggering takes just 3 ms, the remaining 84 ms must be elsewhere in the system!
Low-latency audio, a hard real-time problem
The two other main areas of the system are: the USB/MIDI communication from the Arduino to the PC, and the sound synthesis/playback. USB MIDI should generally be relatively low-latency, and it is a subsystem which we cannot influence so easily – so we focus first on the sound aspects.
Since a PC must be able to do multi-tasking, audio is processed in chunks: a buffer of N samples. This allows some flexibility. However if processing is interruptedfor toolong or too often, the buffer may not be completely filled. The resulting glitch is usually heard as a pop or crackle. The lower latency we want, the smaller the buffer, and the higher chance that something will interrupt for too long. At 96 samples/buffer of 48kHz samplerate, each buffer is just 2 milliseconds long.
With JACK on on Linux
I did the next tests on Linux, since I know it better than Windows. Configuring JACK to 256 samples/buffer, we see that the audio configuration does indeed have a large impact.
Latency reduced to half by configuring Linux with JACK for low-latency audio.
With ASIO4ALL on Windows
But users of the kit are unlikely to use Linux, so a solution that works with Windows is needed (at least). We tried all the different driver options in LMMS, switching to Hydrogen drum machine, as well as attempting to use JACK on Windows. None of these options worked well.
So in the end we tried going with ASIO, using the ASIO4LL replacement drivers. Since ASIO is proprietary LMMS/PortAudio does not support it out-of-the-box. Instead you have to manually replace the PortAudio DLL that comes with LMMS with a custom one 🙁 *nasty*.
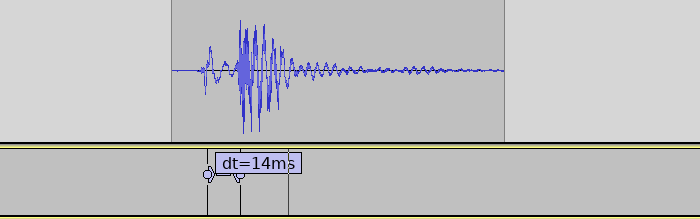
With ASIO4ALL we were able to set the buffer size as low as 96 samples, 2 buffers without glitches.
ASIO on Windows achieves very low latencies. Measurement of single sensor.
Completed system
Bringing back the 8 other sensors again adds around 6 ms to the sensor reading, bringing the final latency to around 20ms. There are likely still possibilities for significant improvements, but the target was reached so this will be good enough for now.
A note on jitter
The variation in latency of a audio system is called jitter. Ideally a musical instrument would have a constant latency (no jitter). When a musical instrument has significant amounts of jitter, it will be harder for the player to compensate for the latency.
Measuring the amount of jitter would require some automated tools for the audio analysis, but should otherwise be doable with the same test setup.
The audio pipeline should have practically no variation, but the USB/MIDI communication might be a source of variation. The CapacitiveSensor Arduino library is known to have variation in sensor readout time, depending on the current capacitance of the sensor.
Conclusions
By recording audible taps of the sensor with a smartphone, and analyzing with a standard audio editor, one can measure end-to-end latency in a tactile-to-sound instrument. A combination of tweaking the sensor hardware layout, improving the Arduino firmware, and configuring PC software for low-latency audio was needed to aceive acceptable levels of latency. The first round of improvements brought the latency down from an ‘almost unplayable’ 134 ms to a ‘hobby-friendly’ 20 ms.
Comparison of latency betwen the different configurations tested.
Embedded systems and microcontroller programs can be really hard to understand. Here are some techniques that can help.
An embedded system is a computer system with a dedicated function within a larger mechanical or electrical system …
– Wikipedia
Examples of embedded systems include everything from a fridge thermostat, to the airbag sensors in your car, to consumer electronics like a electronic keyboard for music. Programming such a system can be extra challenging compared to writing software for a general-purpose computer. The complicating factors may include:
Limited computing power, memory, storage or bandwidth
Need for low and deterministic response times is needed (soft or hard real-time)
Running on battery, within a constrained power budget
Need for high reliability without user intervention over long periods of time (months,years)
A malfunctioning system may cause material damage or harm people
Problem may require considerable domain-specific knowledge
But before all that, we typically need to come to terms with a more mundane and practical problem:
that it is usually very hard to understand what is going on with our program!
Why embedded systems are harder to debug
This problem if hard-to-understand software systems is not at all unique to embedded, it happens frequently also when developing for a PC or mobile device. But several aspects typically make the problem more severe.
It is often hard to stimulate the system with inputs automatically, as they are typically physical/external in nature
Inputs, outputs and internal state of the system may change faster than humans can observe in real-time
The environment of the system typically influences results, sometimes in unforseen ways
Low-level programming languages and techniques is still the norm
The target device does not have a UI or development tools
The connection to a system is often (or at best) a slow serial connection
To make working with the system more pleasant and productive, I have found two techniques very useful:
Recording sensor data from device, and then analyzing it ‘offline’ on the PC
Running the firmware logic on the PC, by abstracting away hardware dependencies
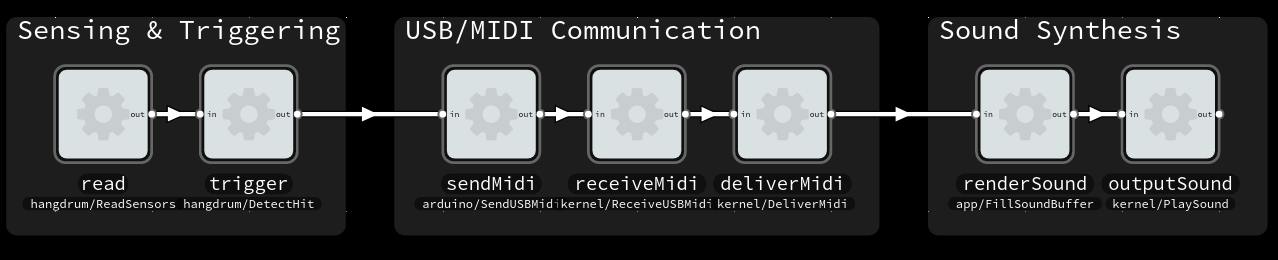
Case: Triggering MIDI with capacitive sensors
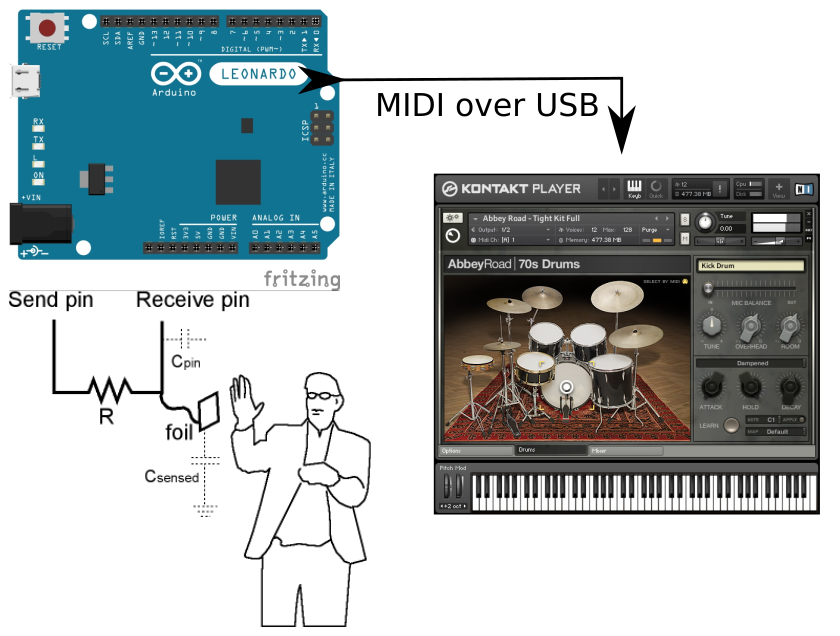
A friend of mine is building a electronic music instrument, a Hang-like thing with 9 pads. It uses capacitive touch sensors and sends MIDI notes over USB for triggering a sampler or synthesizer to make sound.
Core components of system. Capacitive sensor(s) connected to Arduino, sending MIDI messages to computer software over USB.
The firmware on the device was an Arduino sketch, using the CapacitiveSensor library to read the capacitance of the pads.
Summing up N consecutive samples gives basic filtering, and a note is triggered if the value exceedes a specified threshold TH.
The setup worked in principle, and in practice for some ways of hitting the drumpad. But it seemed impossible to find a combination of N and TH where the device would trigger correctly in all cases. If N was too high, then fast taps would be dropped/ignored. If N was low, it caused occational double triggering. If TH was too high, it would not trigger on single finger taps. If TH was too low, it would trigger when a palm was just hovering over the pad.
How to make it work reliably?
To solve a problem, you first have to understand it
Several hours had been spent tweaking the values, recompiling the sketch, uploading and hitting the pads a bit, listening if it did the right thing. This gave us some rough intuitions about things that worked and not, but generally our understanding of the situation was quite sparse. Which is understandable; there is only so much one can learn from observing a system in real-time from the outside with the naked eye/ear.
It seemed that how the pad was hit had an influence. Which is plausible, the surface area might influences how effective the capacitive coupling is.
Example poses that should trigger. Hitting with fingertip, finger flat, 3-fingers and side of thumb.
Some cases which should *not* trigger. Hand hovering over pad, touching casing with thumb but not the pad.
What we needed to understant was: What is the input data in different scenarios?
First added logging to the Arduino sketch, sending the time between readings and the current sensor value (for one sensor).
const long beforeRead = millis();
const Input input = readInputs();
const long afterRead = millis();
Serial.print("(");
Serial.print(afterRead-beforeRead);
Serial.print(",");
Serial.print(input.values[0].capacitance);
Serial.println(")");
The stream showed that with N=70, the reading the sensors took a long time, over 40ms. This is unacceptable for a musical instrument, so it was clear that this value *had* to go down. Any issues caused would have to be fixed in some other way.
Then a small Python script to read the serial port, and writing the raw data to a file.
This allowed us to record the data from a whole scenario. For instance we recorded things like ‘tapping-3-times-quickly’ or ‘hovering-then-touching’, using the filename as a description for what the scenarios was, and directories to group sets of recordings.
Another Python script was then used for analysing the data, parsing the raw values and using matplotlib to plot it out.
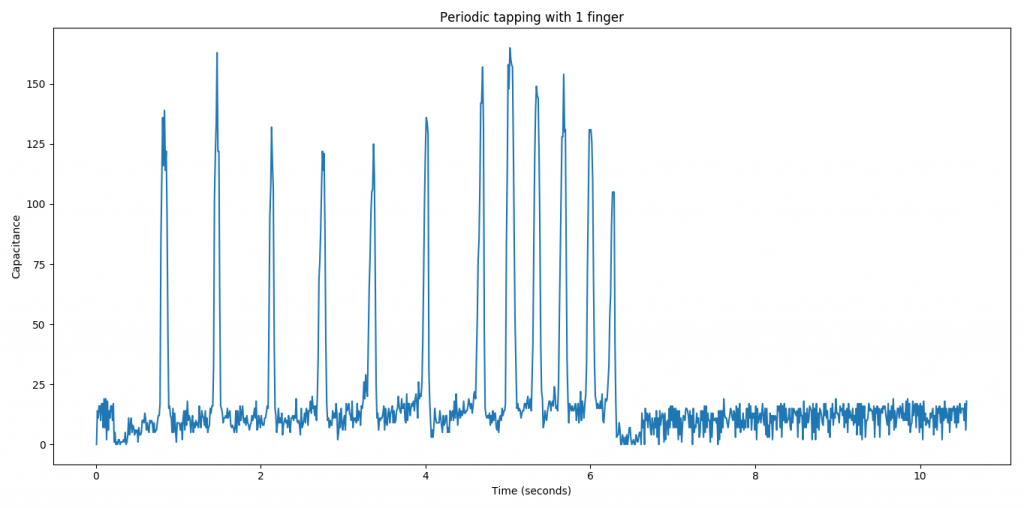
Now we could finally *see* what was going on, over longer periods of time and compare different scenarios against eachother.
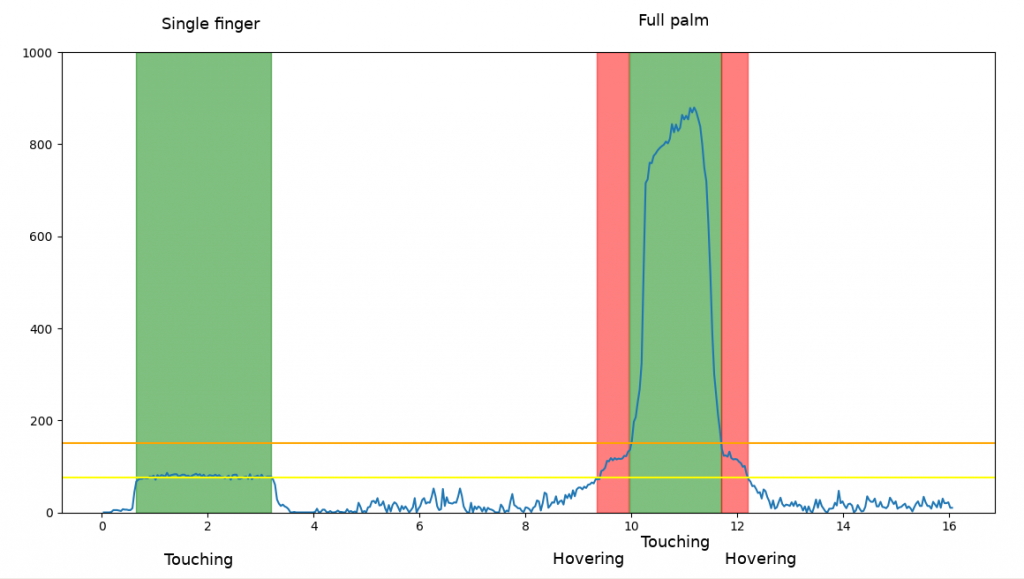
This case illustrated the crux of our problem. The red areas indicate where we are hovering *over* the pad with palm, but the sensed capacitance values are higher than when touching with a fingertip.
If the threshold is set too high (orange line) we miss the finger tap, and if it is too low *yellow) we will false trigger on a hovering palm.
Can we do better with an alternative detection algorithm? Maybe a high-pass filter to detect the changes at the edges, it may be possible be possible to identify both cases. Plugging in a high-pass filter in the Python analysis script and playing with the values seemed to support this.
But we cannot run Python for real-time processing. We need to be able to implement the filter in the Arduino firmware.
Exponential Moving Average filters
An Exponential Moving Average (EMA or EMWA) was selected as the basis of the filter. It has many desirable properties for use in a latency-sensitive application on a microcontroller: It only requires storing one number, is computationally simple, and is robust against variation in sampling time (jitter). And unlike a FIR filter, it does not introduces latency (apart from the time-constant of the filter itself). Here is a nice introduction for Arduino usage.
static int
exponentialMovingAverage(const int value, const int previous, const float alpha) {
return (alpha*value) + ((1-alpha)*previous);
}
...
next.highfilter = exponentialMovingAverage(input.capacitance, previous.highfilter, appConfig.highpass);
next.highpassed = input.capacitance - next.highfilter;
...
What value should highpass have and how do we know if works correctly?
Host-based simulation
A regular Arduino sketch can generally only run on the target microcontroller. This is because the application logic is mixed with the hardware-dependent I/O libraries, in this case CapacitiveSensor and MidiUSB.
But Arduino is just C++. Nothing prevents us from separating out the application logic and making it hardware-independent so it can also execute on our host. The easiest method is to put the code into a .hpp, and then include that in our sketch and any host-only tools we have.
#include "./hangdrum.hpp"
This lets us use all the regular C++ tools and practices for testing and validating code, without needing access to the hardware. Automated unit- and integration-testing, fuzz-testing, mutation testing, dynamic analysis like Valgrind, using a continious integration services like Travis CI. In a project with custom hardware, it lets you develop most parts of the software before the hardware is finalized, potentially saving a lot of time.
I like to express the entire application logic of the firmware as a pure function which takes Input and current State, and returns the new State. This formulation lets us know exactly what may affect the system – no hidden dependencies or state.
State
calculateState(const State &previous, const Input &input, const Config &config) {
State next = previous;
next.time = input.time;
for (unsigned int i=0; i<N_PADS; i++) {
next.pads[i] = calculateStatePad(previous.pads[i], input.values[i], config.pads[i], config);
}
calculateMidiMessages(next, config, next.messages);
return next;
}
Because all the inputs and outputs of the functions are plain-old-data, we can safely and meaningfully serialize and deserialize them.
To get better visibility into the internals of the system and help our understanding, we also store intermediate values:
To store the execution this I used a Flowtrace, a JSON-based format for tracing Flow-based-programming/dataflow system.
Because time is just data in our programming model (part of Input or State), we can run through hours of input scenarios in seconds.
I made another plotting tool, this time reading the flowtrace, visualizing all the steps in our signal processing pipeline, and the detected notes.
Avoiding false triggering for hovering hand, by looking at changes instead of absolute values.
By going over a range of different input scenarios and seeing how different values perform, we get a decent confidence that the algorithm works. But does it actually run fast enough on the Arduino?
Profiling on device
The Atmel AVR chip on the Arduino Leonardo is an 8-bit processor without a floating point unit. So I was a bit worried about the exponential averaging filter using several expensive features: 16bit `int`, divisions and a multiplication with a float. Using a Arduino sketch to do some simple profiling showed that my worries were unfounded.
const long beforeCalculation = millis();
State next = state;
for (int i=0; i<100; i++) {
next = hangdrum::calculateState(state, input, config);
}
state = next;
const long afterCalculation = millis();
Serial.print("calculating: ");
Serial.println(afterCalculation-beforeCalculation);
The 100 iterations of the application logic executed it took 80 ms with both a high-pass and low-pass, or less than 1ms per execution. Since sensor readout is up to 10 ms, it dominates the time spent. So if we want lower latency, optimization efforts should be focused on sensor readout first. Only when sensor readout is down to around 1ms does it make sense to optimize the filtering.
Don’t forget the hardware
Testing the code with highpass-based in practice showed that yes, it did correctly detect tapping while supressing false triggers from a hovering palm over the sensor. Another benefit when using change detection a notes will trigger even if a finger is currently touching, and hitting the pad with another finger. With absolute value thresholding, the second finger tap is not detected.
However, we also found that by moving the sensor to the outside, the data quality increases a lot. In this case, even the simple absolute threshold code was able to correctly discriminate a hovering palm. The higher data quality may also enable other features like velocity or aftertouch.
Putting sensor on outside of body gives better readings, but requires additional manufacturing steps.
In conclusion
Sensor-recording together with a separting hardware from application logic, and host-based simulation form powerful tools that help you better understand an embedded system. By visualizing the input data, the internal state and the outputs of the firmware, you can more easily see and understand the conditions which cause problems. The effects of changing the firmware can be quickly understood, as re-running the simulation suite on a wide range of inputs can be done in seconds. It can be implemented easily in C++ firmware, and any scripting language can be used for the data analysis.
The techniques here form a baseline level of tooling which can be extended in many ways.
If we had recorded a high-framerate video stream together with the input data, it would be easier to see how the input data corresponds to physical actions.
We could annotate the input data to indicate the correct locations of notes (expected output of system), and write an automated test against the output trace to check how well the firmware detects them. By using data-driven testing, we could generate test variations over different inputs and filter configuration. And then use machine learning techniques to help find the best values for the filters.
We could also create an end-to-end test covering the vast majority of the code by inject input sensor data in the on-device firmware over serial, and then verify that it produces the expected MIDI messages.
Automated testing is a key part of software development toolkit and practice. fbp-spec is a testing framework especially designed for Flow-based Programming(FBP)/dataflow programming, which can be used with any FBP runtime.
For imperative or object-oriented code good frameworks are commonly available. For JavaScript, using for example Mocha with Chai assertions is pretty nice. These existing tools can be used with FBP also, as the runtime is implemented in a standard programming language. In fact we have used JavaScript (or CoffeeScript) with Mocha+Chai extensively to test NoFlo components and graphs. However the experience is less nice than it could be:
A high degree of amount of setup code is needed to test FBP components
Mental gymnastics when developing in FBP/dataflow, but testing with imperative code
The most critical aspects like inputs and expectations can drown in setup code
In FBP, code exists as a set of black-box components. Each component defines a set of inports which it receives data on, and a set of outports where data is emitted. Internal state, if any, should be observable through the data sent on outports.
A trivial FBP component
So the behavior of a component is defined by how data sent to input ports causes data to be emitted on output ports.
An fbp-spec is a set of testcases: Examples of input data along with the corresponding output data that is expected. It is stored as a machine-readable datastructure. To also make it nice to read/write also for humans, YAML is used as the preferred format.
This kind of data-driven declaration of test-cases has the advantage that it is easy to see which things are covered – and which things are not. What about numbers? What about falsy cases? What about less obvious situations like passing { x: 3.0, y: 5.0 }?
And it would be similarly easy to add these cases in. Since unit-testing is example-based, it is critical to cover a diverse set of examples if one is to hope to catch the majority of bugs.
equals here is an assertion function. A limited set of functions are supported, including above/below, contains, and so on. And if the data output is a compound object, and possibly not all parts of the data are relevant to check, one can use a JSONPath to extract the relevant bits to run the assertion function against. There can also be multiple assertions against a single output.
A FBP component should, when possible, be state-free and not care about message ordering. However it is completely legal, and often useful to have stateful components. To test such a component one can specify a sequence of multiple input packets, and a corresponding expected output sequence.
This still assumes that the component sends one set of packet out per input packet in. And that we can express our verification with the limited set of assertion operators. What if we need to test more complex message sending patterns, like a component which drops every second packet (like a decimation filter)? Or what if we’d like to verify the side-effects of a component?
Fixtures using FBP graphs
The format of fbp-spec is deliberately simple, designed to support the most common axes-of-freedom in tests as declarative data. For complex assertions, complex input data generation, or component setup, one should use a FBP graph as a fixture.
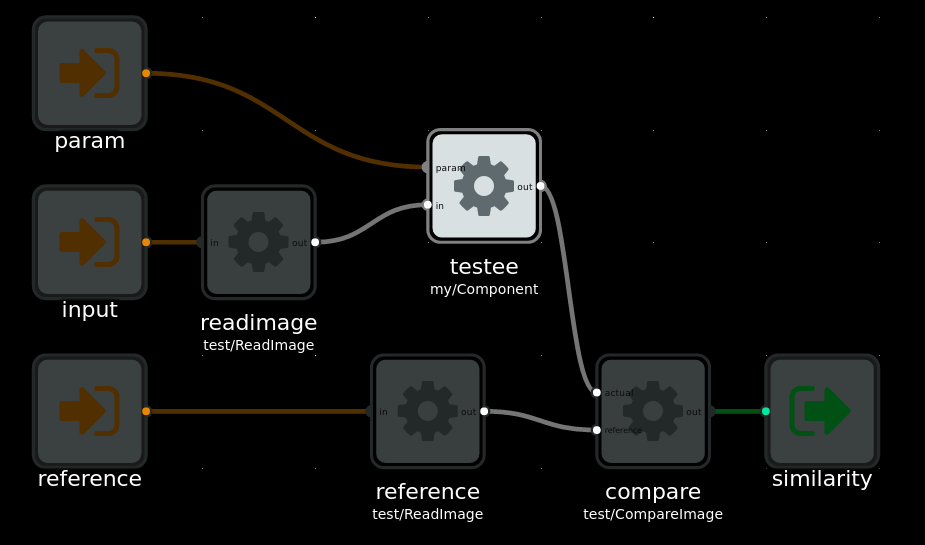
For instance if we wanted to test an image processing operation, we may have reference out and input files stored on disk. We can read these files with a set of components. And another component can calculate the similarity between the processed out, as a number that we can assert against in our testcases. The fixture graph could look like this:
Example fixture for testing image processing operation, as a FBP graph.
This can be stored using the .FBP DSL into the fbp-spec YAML file:
topic: my/Component
fixture:
type: 'fbp'data: | INPORT=readimage.IN:INPUT INPORT=testee.PARAM:PARAM INPORT=reference.IN:REFERENCE OUTPORT=compare.OUT:SIMILARITY readimage(test/ReatImage) OUT -> IN testee(my/Component) testee OUT -> ACTUAL compare(test/CompareImage) reference(test/ReadImage) OUT -> REFERENCE compare
cases:
-name: 'testing complex data with custom components fixture'assertion: 'should pass'inputs:
input: someimageparam: 100reference: someimage-100-resultexpect:
similarity:
above: 0.99
Since FBP is a general purpose programming system, you can do arbitrarily complex things in such a fixture graph.
Flowhub integration
The Flowhub IDE is a client-side browser application. For it to actually cause changes in a live program, it communicate using the FBP runtime protocol to the FBP runtime, typically over WebSocket. This standardized protocol is what makes it possible to program such diverse targets, from webservers in Node.js, to image processing in C, sound processing with SuperCollider, bare-metal microcontrollers and distributed systems. And since fbp-spec uses the same protocol to drive tests, we can edit & run tests directly from Flowhub.
This gives Flowhub a basic level of integrated testing support. This is useful right now, and unlocks a number of future features.
On-device testing with MicroFlo
When programming microcontrollers, automated testing is still not as widely used as in web programming, at least outside very advanced or safety-critical industries. I believe this is largely because the tooling is far from as good. Which is why I’m pretty excited about fbp-spec for MicroFlo, since it makes it exactly as easy to write tests that run on microcontrollers as for any other FBP runtime.
Testing microcontroller code using fbp-spec
To summarize, with fbp-spec 0.2 there is an easy way to test FBP components, for any runtime which supports the FBP runtime protocol (and thus anything Flowhub supports). Check the documentation for how to get started.
Last weekend at FOSDEM I presented in the Internet of Things (IoT) devroom,
showing how one can use MsgFlo with Flowhub to visually live-program devices that talk MQTT.
Since announcing MsgFlo in 2015, it has mostly been used to build scalable backend systems (“cloud”), using AMQP and RabbitMQ. At The Grid we’ve been processing hundred thousands of jobs each week, so that usecase is pretty well tested by now.
However, MsgFlo was designed from the beginning to support multiple messaging systems (including MQTT), as well as other kinds of distributed systems – like a networks of embedded devices working together (one aspect of “IoT”). And in MsgFlo 0.10 this is starting to work pretty nicely.
Visual system architecture
Typical MQTT devices have the topic names hidden in code. Any documentation is typically kept in sync (or not…) by hand.
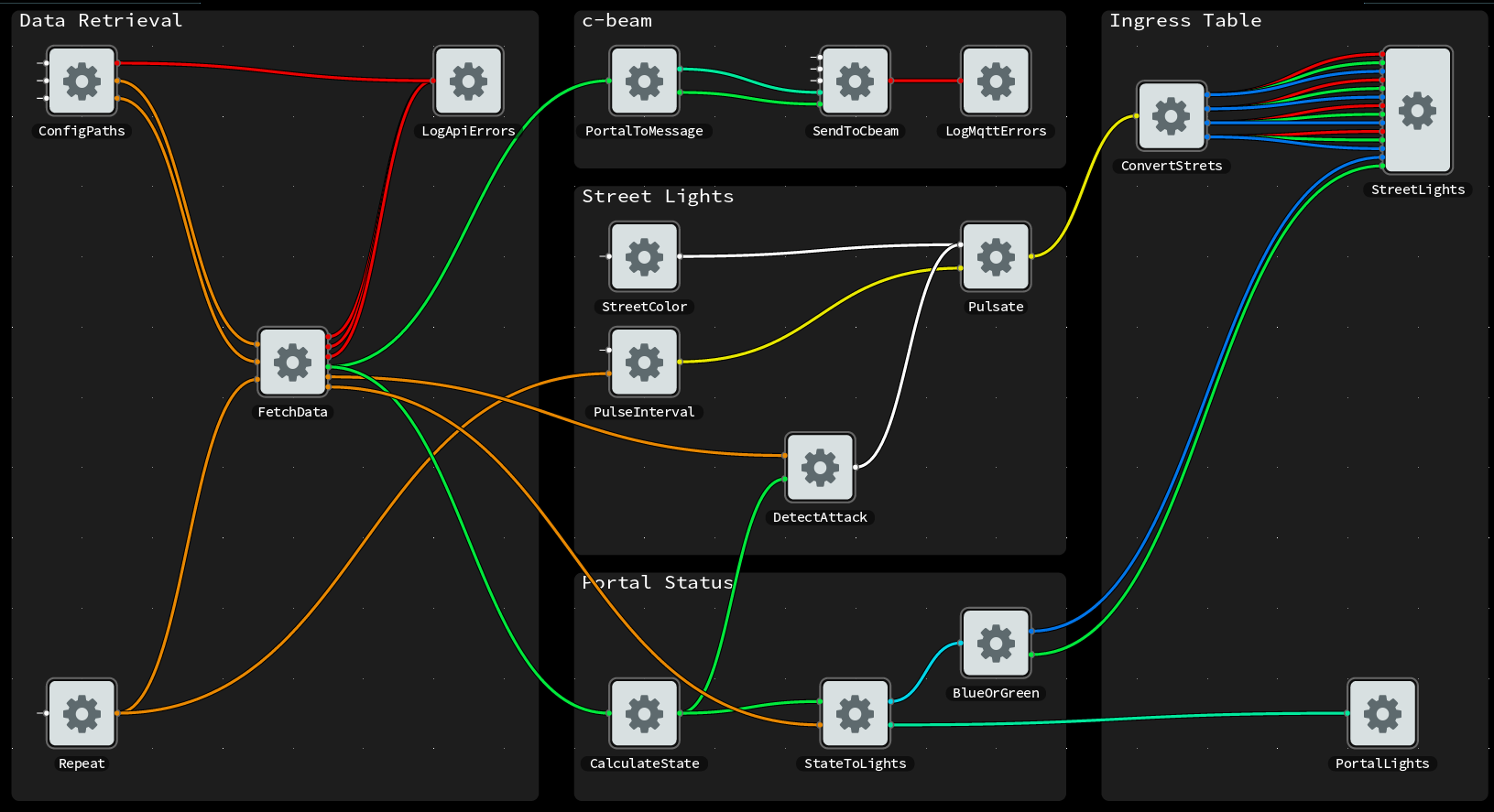
MsgFlo lets you represent your devices and services as FBP/dataflow “components”, and a system as a connected graph of component instances. Each device periodically sends a discovery message to the broker. This message describing the role name, as well as what ports exists (including the MQTT topic name). This leads to a system architecture which can be visualized easily:
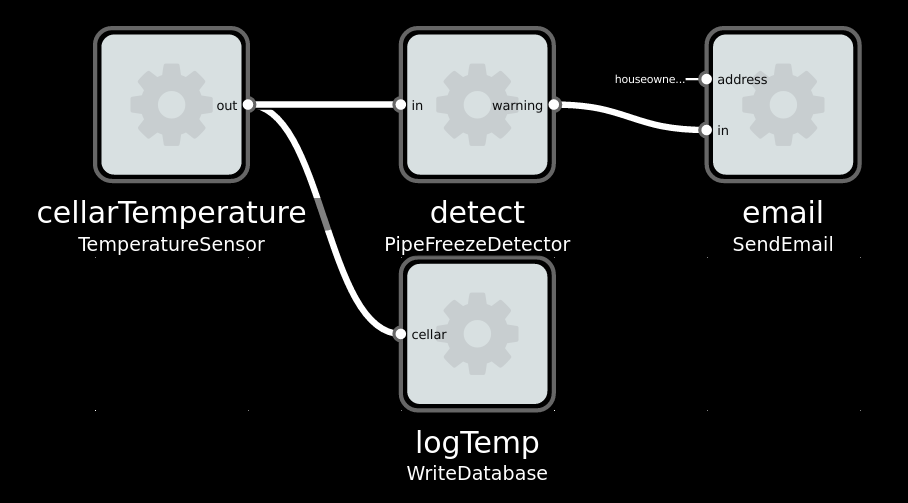
Imaginary solution to a typically Norwegian problem: Avoiding your waterpipes freezing in the winter.
Rewire live system
In most MQTT devices, output is sent directly to the input of another device, by using the same MQTT topic name. This hardcodes the system functionality, reducing encapsulation and reusability.
MsgFlo each device *should* send output and receive inports on topic namespaced to the device.
Connections between devices are handled on the layer above, by the broker/router binding different topics together. With Flowhub, one can change these connections while the system is running.
Change program values on the fly
Changing a parameter or configuration of an embedded device usually requires changing the code and flashing it. This means recompiling and usually being connected to the device over USB. This makes the iteration cycle pretty slow and tedious.
In MsgFlo, devices can (and should!) expose their parameters on MQTT and declare them as inports.
Then they can be changed in Flowhub, the device instantly reflecting the new values.
Great for exploratory coding; quickly trying out different values to find the right one.
Examples are when tweaking animations or game mechanics, as it is near impossible to know up front what feels right.
Add component as adapters
MsgFlo encourages devices to be fairly stupid, focused on a single generally-useful task like providing sensor data, or a way to cause actions in the real world. This lets us define “applications” without touching the individual devices, and adapt the behavior of the system over time.
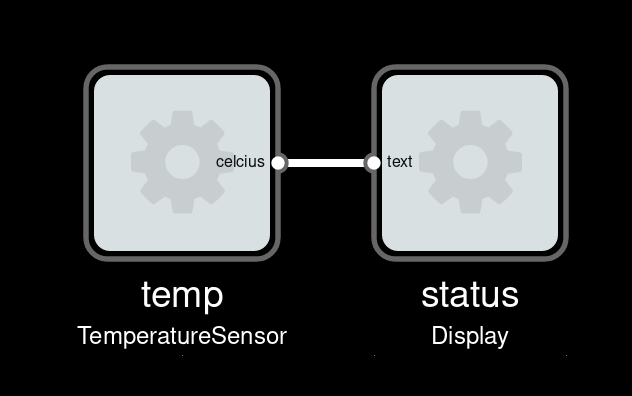
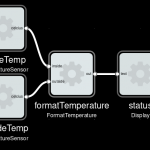
Imagine we have a device which periodically sends current temperature, as a floating-point number in Celcius unit. And a display device which can display text (for instance a small OLED). To show current temperature, we could wire them directly:
Our display would show something like “22.3333333”. Not very friendly, how does one know what this number means?
Better add a component to do some formatting.
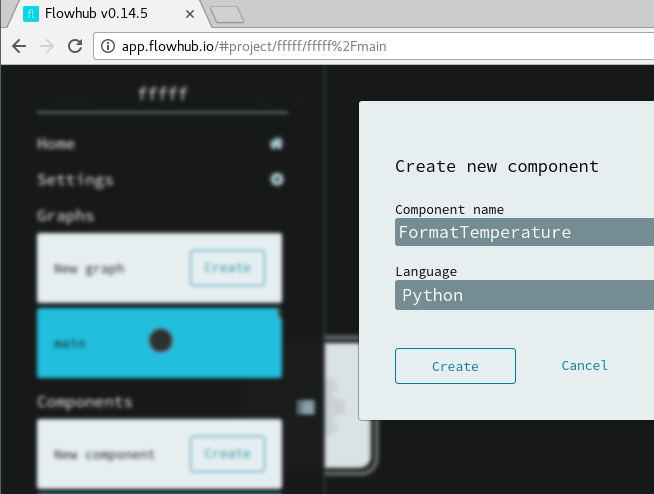
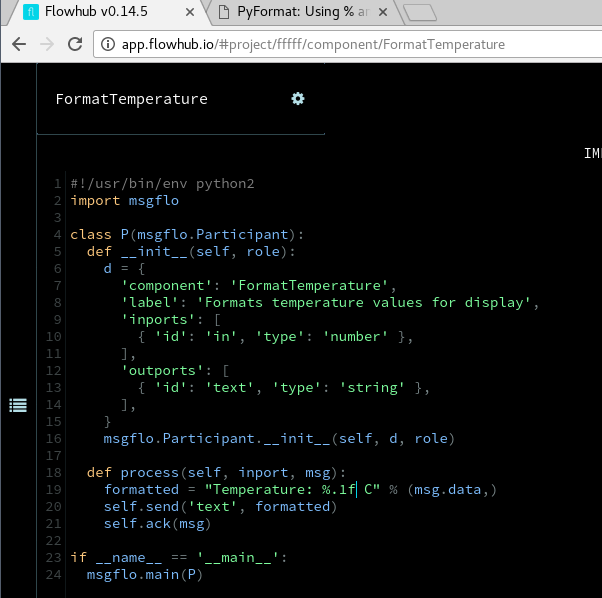
Adding a Python component
Component formatting incoming temperature number to a friendly text string
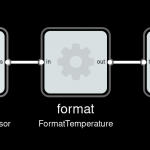
And then insert it before the display. This will create a new process, and route the data through it.
Our display would now show “Temperature: 22.3 C”
Over time maybe the system grows further
Added another sensor, output now like “Inside 22.2 C Outside: -5.5 C”.
Getting started with MsgFlo
If you have existing “things” that support MQTT, you can start using MsgFlo by either:
1) Modifying the code to also send the discovery message.
2) Use the msgflo-foreign-participant tool to provide discovery without code changes
If you have new things, using one of the MsgFlo libraries is a quick way to support MQTT and MsgFlo. Right now there are libraries for Python, C++11, Node.js, NoFlo and Arduino.
At The Grid we do a lot of computationally heavy work server-side, in order to produce websites from user-provided content. This includes image analytics (for understanding the content), constraint solving (for page layout) and image processing (optimization and filtering to achieve a particular look). Currently we serve some thousand sites, with some hundred thousands sites expected by the time we’ve completed beta – so scalability is a core concern.
All computationally intensive work is put as jobs in a AMQP/RabbitMQ message queue, which are consumed by Heroku workers. To make it easy to manage many queues and worker roles we also use MsgFlo.
This provides us with the required flexibility to scale: the queues buffer the in-progress work, broker distributes evenly between available workers, and with Heroku we can change number of workers with one command. But, it still leaves us with the decision on how much compute capacity to provision. And when load is dynamic, it is tedious & inefficient to do it manually – especially as Heroku bills workers used by the second.
Monitoring RabbitMQ queues and scaling Heroku workers manually when demand changes; not fun.
If we would instead regulate this every 1-5 minute based on demand, we would reduce costs. Or alternatively, with a fixed budget, provide a better quality-of-service. And most importantly, let developers worry about other things.
Of course, there already exists a number of solutions for this. However, some used particular metrics providers which we were not using, some used metrics with unclear relationship to required workers (like number of users), or had unacceptable limitations (only one worker per service, only run as a service with pay-by-number-of-workers).
guv
guv 0.1 implements a simple proportional scaling model. Based the current number of jobs in the queue, and an estimate of job processing time – it calculates the number of workers required for all work to be completed within a configured deadline.
The deadline is the maximum time you allow for your users to wait for a completed job. The job processing time [average, deviation] can be calculated from metrics of previous jobs. And the number of jobs in queue is read directly from RabbitMQ.
# A simple guv config for one worker role.
# One guv instance typically manages many worker roles
'*':
app: my-heroku-app
analyze:
queue: 'analyze.IN' # RabbitMQ queue name
worker: analyzeworker # Heroku dyno role name
process: 20
deadline: 120.0
min: 1 # keep something always running
max: 15 # budget limits
Now there are a couple limitations of this model. Primarily, it is completely reactive; we do not attempt to predict how traffic will develop in the future. Prediction is after all terribly tricky business – better not go there if it can be avoided.
And since it takes a non-zero amount of time to spin up a new worker (about 45-60 seconds), on a sudden spike in demand may cause some jobs to miss a tight deadline, as the workers can’t spin up fast enough. To compensate for this, there is some simple hysteresis: scale up more aggressively, and scale down a bit reluctanctly – we might need the workers next couple of minutes.
As a bonus, guv includes some integration with common metrics services: The statuspage.io metrics about ‘jobs-in-flight’ on status.thegrid.io, come directly from guv. And using New Relic Insights, we can analyze how the scaling is performing.
Last 2 days of guv scaling history on some of the workers roles at The Grid.
If we had a manual scaling with a constant number over 48 hours period, workers=35 (Max), then we would have paid at least 3-4 times more than we did with autoscaling (difference in size of area under Max versus area under the 10 minute line). Alternatively we could have provisioned a lower number of workers, but then with spikes above that number – our users would have suffered because things would be taking longer than normal.
We’ve been running this in production since early June. Back then we had 25 users, where as now we have several thousand. Apart from updating the configuration to reflect service changes we do not deal with scaling – the minute to minute decisions are all done by guv. Not much is planned in terms of new features for guv, apart from somemoretools to analyze configuration. For more info on using guv, see the README.
At The Grid we do a lot of CPU intensive work on the backend as part of producing web pages. This includes content extraction, normalization, image analytics, webpage auto-layout using constraint solvers, webpage optimization (GSS to CSS compilation) and image processing.
The system runs on Heroku, and spreads over some 10 different dyno roles, communicating between each other using AMQP message queues. Some of the dyno separation also deals with external APIs, allowing us to handle service failures and API rate limiting in a robust manner.
Majority of the workers are implemented using NoFlo, a flow-based-programming for Node.js (and browser), using Flowhub as our IDE. This gives us a strictly encapsulated, visual, introspectable view of the worker; making for a testable and easy-to-understand architecture.
Inside a process: In NoFlo each node is a JavaScript class
However NoFlo is only concerned about an individual worker process: it does not comprehend that it is a part of a bigger system.
Enter MsgFlo
MsgFlo is a new FBP runtime designed for distributed systems. Each node represents a separate process, and the connections (edges) between nodes are message queues in a broker process.
To make this distinction clearer, we’ve adopted the term participant for a node which participates in a MsgFlo network.
Because MsgFlo implements the same FBP runtime protocol and JSON graph format as NoFlo, imgflo, MicroFlo – we can use the same tools, including the .FBP DSL and Flowhub IDE.
Distributed MsgFlo system: HTTP frontends + workers in separate processes.
The graph above represents how different roles are wired together. There may be 1-N participants in the same role, for instance 10 dynos of the same dyno type on Heroku.
There can also be multiple participants in a single process. This can be useful to make different independent facets show up as independent nodes in a graph, even if they happen to be executing in the same process. One could use the same mechanism to implement a shared-nothing message-passing multithreading model, with the limitation that every message will pass through a broker.
Connections have pub-sub semantics, so generally each of the individual dynos will receive messages sent on the connection.
The special component msgflo/RoundRobin specifies that messages should be delivered in a round-robin fashion: new message goes only to the next process in that role with available capacity. The RoundRobin component also supports dead-lettering, so failed jobs can be routed to another queue. For instance to be re-processed at a later point automatically, or manually after developers have located and fixed the issue. This way one never loose pending work.
On AMQP roundrobin delivery and deadlettering can be fulfilled by the broker (e.g. RabbitMQ), so there is no dedicated process for that node.
Messaging systems
People use different messaging systems. We’ve tried to make sure that MsgFlo architecture and tools can be used with many different. The format and delivery of discovery messages is specified, and the tools have a transport abstraction layer. Currently there is production-level support for AMQP 0-9-1 (tested with RabbitMQ). Basic support exists for MQTT, a simple protocol popular in distributed “Internet-of-Things” type systems. Support for more transports can be added by implementing two classes.
Polyglot participation
MsgFlo itself only handles the discovery of participants and setup of the connections between them, as well as providing debug capabilities like Flowhub endpoint support. Having participants in a particular language requires implementing . We do provide a set of libraries that makes this easy for popular languages:
Using noflo-runtime-msgflo makes it super simple to use NoFlo as MsgFlo participants. The exported ports of the NoFlo graph or component (for instance ‘in’, ‘out’, and ‘error’) will be automatically made available as queues in MsgFlo, and one can connect this into a bigger system.
In addition to node.js and NoFlo, there is basic participant support provided for Python and for C++ (with AMQP). It took about about half a day and 2-300 lines of code, so adding support for more languages should be pretty simple. There are even tests you can reuse.
Since MsgFlo 0.3, we are using MsgFlo in production for all workers across The Grid backends. After migrating we’ve also moved more things into dedicated participants, because we now have the tooling that makes managing that complexity easy. Our short term focus now is more tools around MsgFlo, like deadline-based autoscaling and integration of data-driven testing using fbp-spec. Features planned for MsgFlo itself includes live introspection of messages in Flowhub.
Looking further ahead, we would like to make more use of the polyglot capabilities, for instance by move some of our image analytics out from NoFlo/node.js participants (with C/C++ libs) to pure C++ 11 participants.
I also hope to do some fun projects with MQTT and MicroFlo – and validate MsgFlo for Embedded/Internet-of-Things-type.
Time for a new release of imgflo, the image processing server and dataflow runtime based on GEGL. This iteration has been mostly focused on ironing out various workflow issues, including documentation. Primarily so that the creatives in our team can be productive in developing new image filters/processing. Eventually this will also be an extension point for third parties on our platform.
By porting the png and jpeg loading operations in GEGL to GIO, we’ve added support for loading images into imgflo over HTTP or dataURLs. The latter enables opening local file through a file selector in Flowhub. Eventually we’d like to also support picking from web services.
Loading local file using HTML5 input type=”file”
Another big feature is allowing to live-code new GEGL operations (in C) and load them. This works by sending the code over to the runtime, which then compiles it into a new .so file and loads it. Newly instatiated operations then uses that revision of code. We currently do not change the active operation of currently running instances, though we could.
Operations are never unloaded, due both to a glib limitation and the general trickyness of guaranteeing this to be safe for native code. This is not a big deal as this is a development-only feature, and the memory growth is slow.
Live-coding new image processing operations in C
imgflo now supports showing the data going through edges, which is very useful to understand how a particular graph works.
Selecting edges shows the buffer at that point in the graph
Using Heroku one can get started without installing anything locally. Eventually we might have installers for common OS’es as well.
Get started with imgflo using Heroku
Vilson Viera added a set of new image filters to the server, inspired by Instagram. Vilson is also working on our image analytics pipeline, the other piece required for intelligent automatic- and semi-automatic image processing.
GEGL has for a long time supported meta-operations: operations which are built as a sub-graph of other operations. However, they had to be built programatically using the C API which limited tooling support and the platform-specific nature made them hard to distribute.
Now GEGL can load such operations from the JSON format also used by imgflo (and severalotherruntimes). This lets one use operations built with Flowhub+imgflo in GIMP:
This makes Flowhub+imgflo a useful tool also outside the web-based processing workflow it is primarily built for. Feature is available in GEGL and GIMP master as of last week, and will be released in GIMP 2.10 / GEGL 0.3.
Next iteration will be primarily about scaling out. Both allowing multiple “apps” (including individual access to graphs and usage monitoring/quotas) served from a single service, and scaling performance horizontally. The latter will be critical when the ~20k+ users who have signed up start coming onboard.
If you have an interest in using our hosted imgflo service outside of The Grid, get in contact.